
今天来了解一点新的东西
可变参数
之前讲函数的时候忘记了这个可变参数,不过说实话我感觉这玩意会诞生估计是lua语言制作者用来偷懒的
这个东西某种程度上还挺好用的,但是只能在函数function里使用
正常的代参函数是这样的
1 | local function numberAdd(a, b, c) |
但是假如我们传入的参数贼多,这时候就可以使用 “…”
1 | local function numberAdd(...) |
还可以这样在里面加上固定参数,固定参数必须放在可变参数之前
1 | function hello(hi, ...) ---> 固定的参数hi |
我们可以看到可变参数…使用方法和表没有区别,如果使用#来获取…的长度,那么…参数里就不能出现nil,否则nil会被忽略
通常在遍历变长参数的时候只需要使用 {…},然而变长参数可能会包含一些 nil,那么就可以用 select 函数来访问变长参数了:select(‘#’, …) 或者 select(n, …)
- select(‘#’, …) 返回可变参数的长度
- select(n, …) 用于返回从起点 n 开始到结束位置的所有参数列表
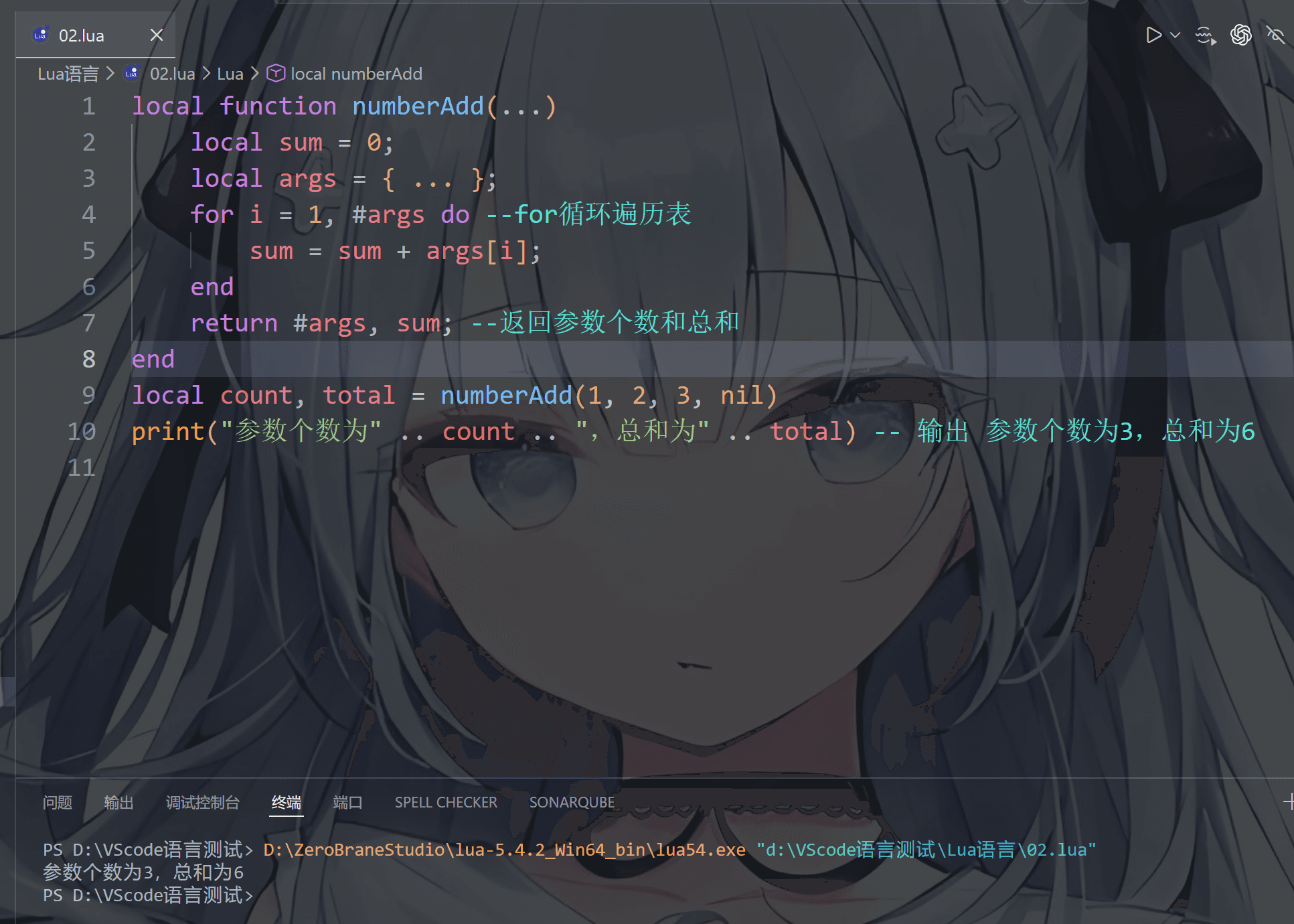
1 | local function numberAdd(...) |
select(“#”,…)或select(‘#’,…)统计传入参数总数
这时候我们可以使用select("#",...)或者select('#',...),就可以返回可变参数的真实数量了包括nil
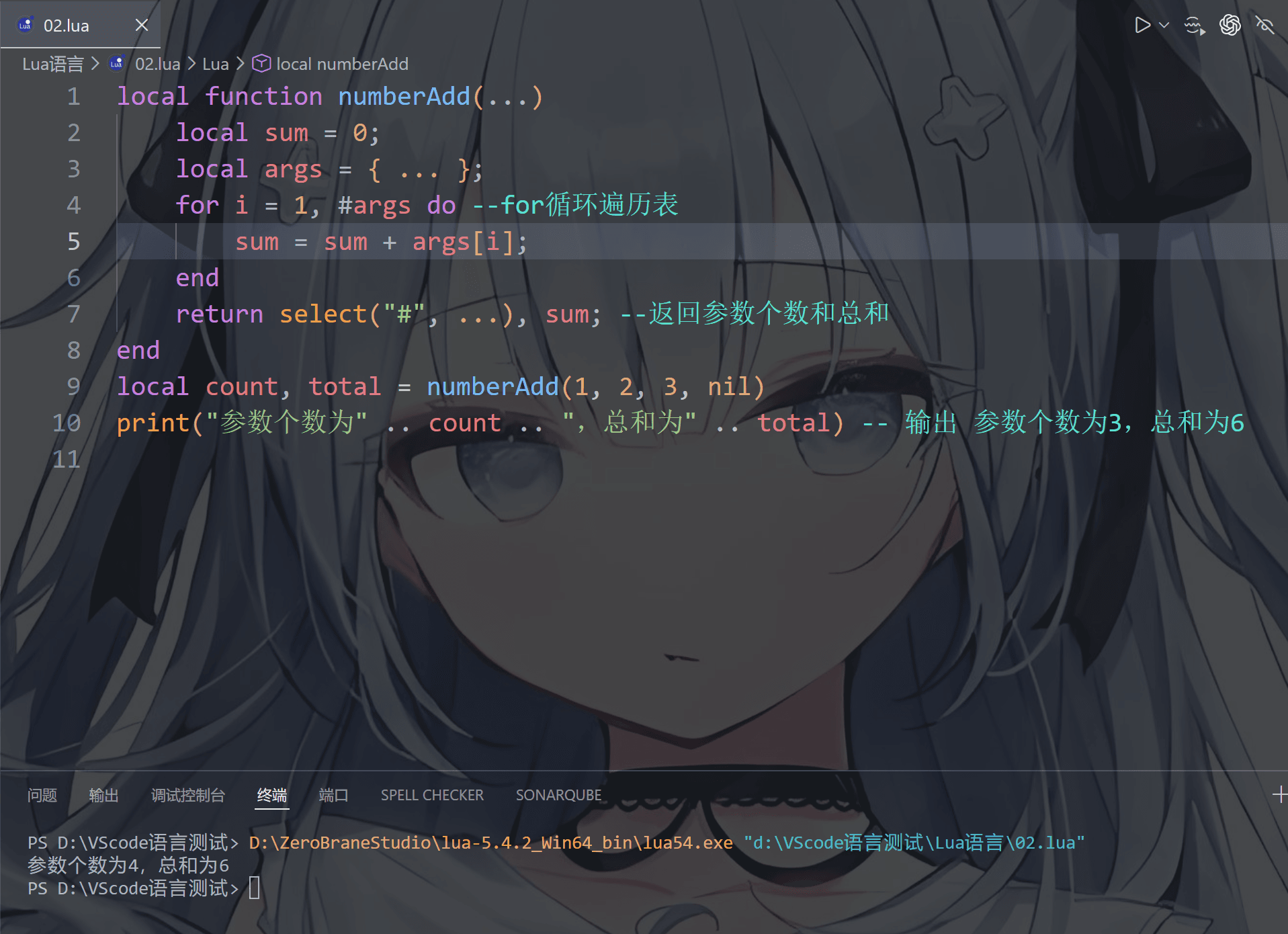
1 | local function numberAdd(...) |
select(n,…)返回从第n个参数和其后的所有参数
1 | function args(...) |

1 | local t = {select(1, ...)} |
所以可变参数就是
① … 是一堆参数
② {…}是把参数变成表,返回值是地址
③ select是精确操作参数
运算符
算术运算符
| 操作符 | 描述 | 实例(A=10,B=20) |
|---|---|---|
| + | 加法 | A + B 输出结果 30 |
| - | 减法 | A - B 输出结果 -10 |
| * | 乘法 | A * B 输出结果 200 |
| / | 除法 | B / A 输出结果 2 |
| % | 取余 | B % A 输出结果 0 |
| ^ | 乘幂 | A^2 输出结果 100 |
| - | 负号 | -A 输出结果 -10 |
| // | 整除运算符(>=lua5.3) | 5//2 输出结果 2 |
⚠️在 lua 中,/ 用作除法运算,计算结果包含小数部分,// 用作整除运算,计算结果不包含小数部分,也就是取整
关系运算符
| 操作符 | 描述 | 实例(A=10,B=20) |
|---|---|---|
| == | 等于,检测两个值是否相等,相等返回 true,否则返回 false | (A == B) 为 false |
| ~= | 不等于,检测两个值是否相等,不相等返回 true,否则返回 false | (A ~= B) 为 true |
| > | 大于,如果左边的值大于右边的值,返回 true,否则返回 false | (A > B) 为 false |
| < | 小于,如果左边的值大于右边的值,返回 false,否则返回 true | (A < B) 为 true |
| >= | 大于等于,如果左边的值大于等于右边的值,返回 true,否则返回 false | (A >= B) 返回 false |
| <= | 小于等于, 如果左边的值小于等于右边的值,返回 true,否则返回 false | (A <= B) 返回 true |
逻辑运算符
| 操作符 | 描述 | 实例(A=10,B=20) |
|---|---|---|
| and | 逻辑与操作符。 若 A 为 false,则返回 A,否则返回 B | (A and B) 为 false |
| or | 逻辑或操作符。 若 A 为 true,则返回 A,否则返回 B | (A or B) 为 true |
| not | 逻辑非操作符。与逻辑运算结果相反,如果条件为 true,逻辑非为 false | not(A and B) 为 true |
其他运算符
| 操作符 | 描述 | 实例 |
|---|---|---|
| .. | 连接两个字符串 | a..b ,其中 a 为 “Hello “ , b 为 “World”, 输出结果为 “Hello World” |
| # | 一元运算符,返回字符串或表的长度。 | #”Hello” 返回 5 |
运算符优先级
从上到下优先级依次降低
1 | ^ |
字符串函数
字符串这个我们之前已经讲过了一部分,这里系统学习一下有关字符串的函数吧
①字符串长度计算
1 | string.len() ASCII计算 |
Lua 中,要计算字符串的长度(即字符串中字符的个数),可以使用 string.len 函数或 utf8.len 函数
计算包含中文的字符串一般用 utf8.len,
计算只包含 ASCII 字符串的长度用 string.len,UTF-8 中文 = 3字节
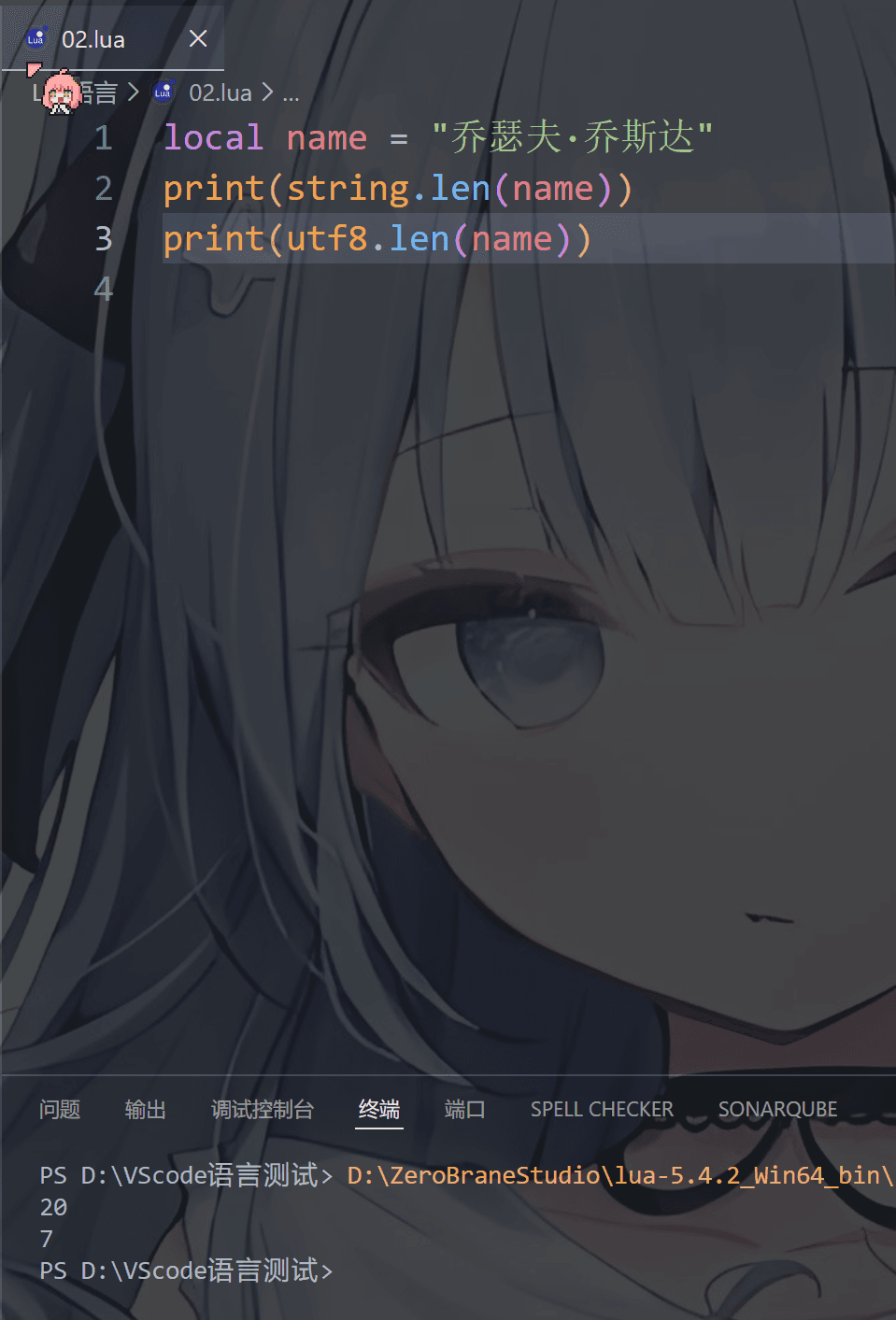
可以看出string.len是按照字节数计算的,而utf8.len是按照字符的个数计算的
② 字符串英文大小写转换
1 | string.upper() 小写转大写 |

③ 替换字符串里的元素
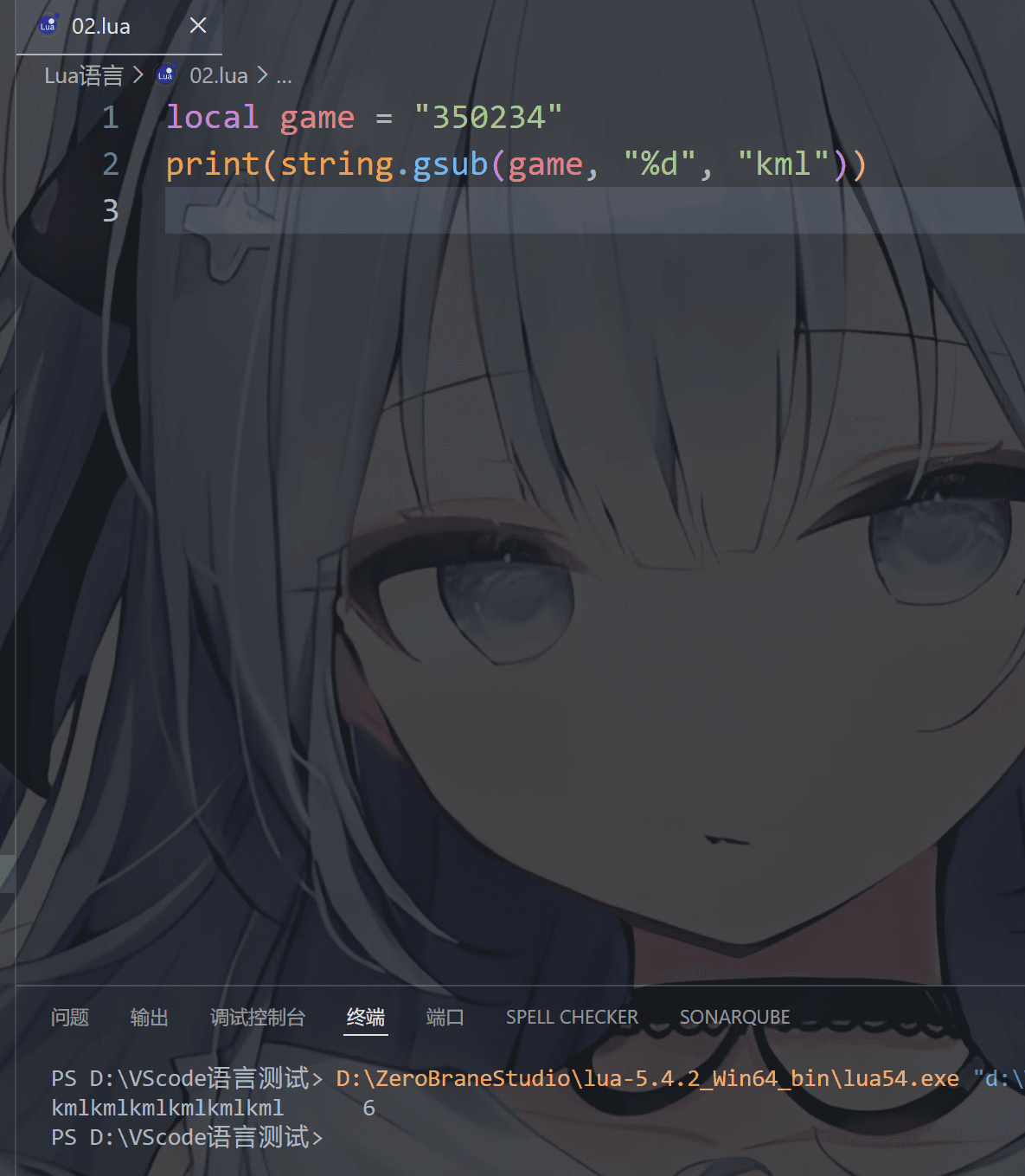
1 | string.gsub(main, find, replace, num) |
参数解释:
main:原字符串find:要找的内容(支持模式匹配)replace:替换成什么num:替换次数(可选,不写 = 全部替换)
这么说你们可能看不懂
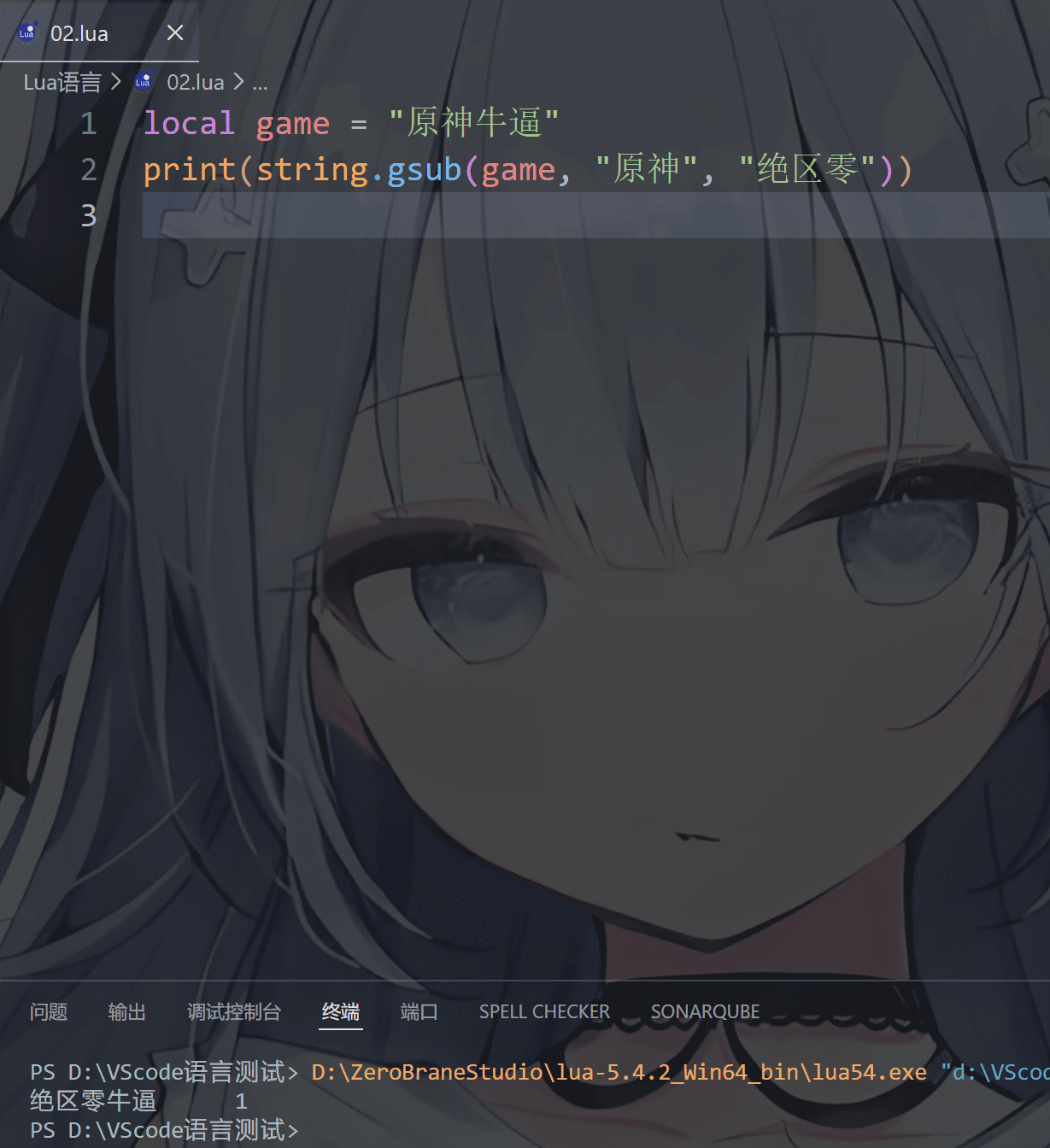
这下你们理解了吧,可以看到返回值有两个
返回值1:新字符串
返回值2:替换次数
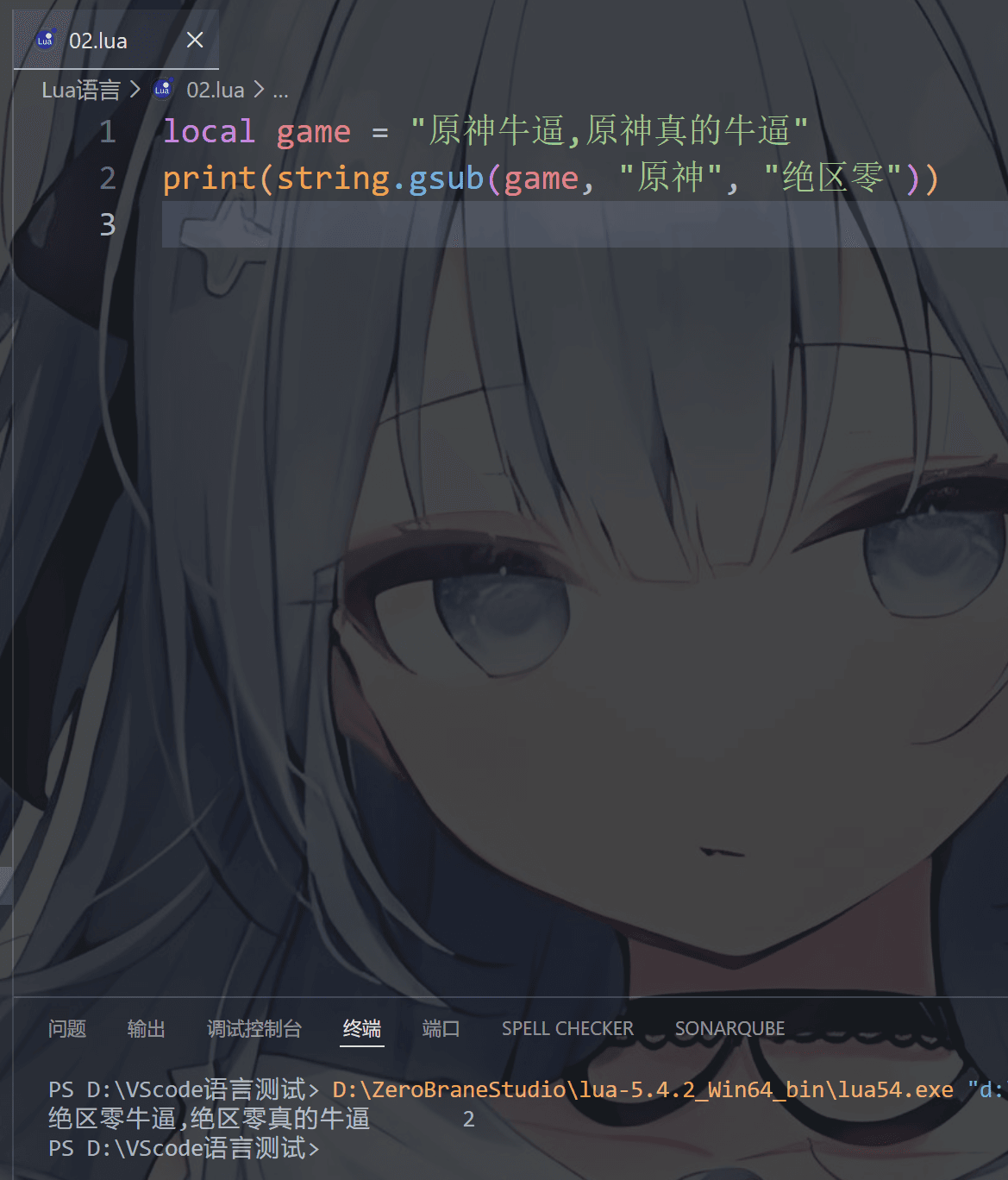
我们还可以这么玩,就是利用模式匹配,%d为数字
1 | string.gsub("2026-02-10", "(%d+)%-(%d+)%-(%d+)", "%3/%2/%1") |
这个后面会细说这个模式匹配的事
④ 查找字符串子串位置(索引)
1 | string.find(str, substr, [init], [plain]) |
参数:
str: 原字符串
substr:要查找的字符串
init:开始位置(默认1)
plain:
true:普通查找(不使用模式)
false:模式匹配(正则风格,默认)
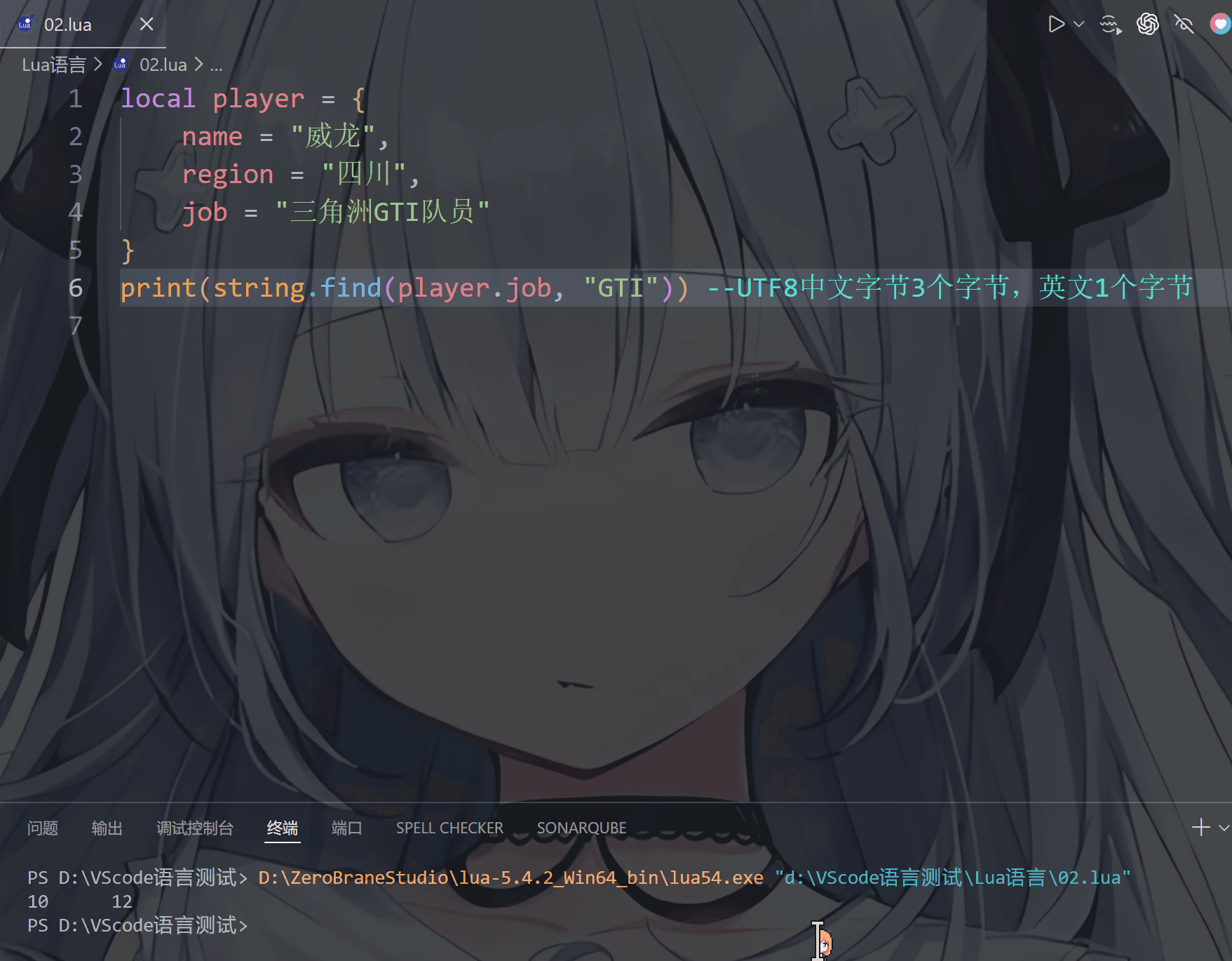
返回值1: 要查找的字符串在原字符串中的开始位置
返回值2:要查找的字符串在原字符串中的结束位置
1 | -- +号是正则符号 |
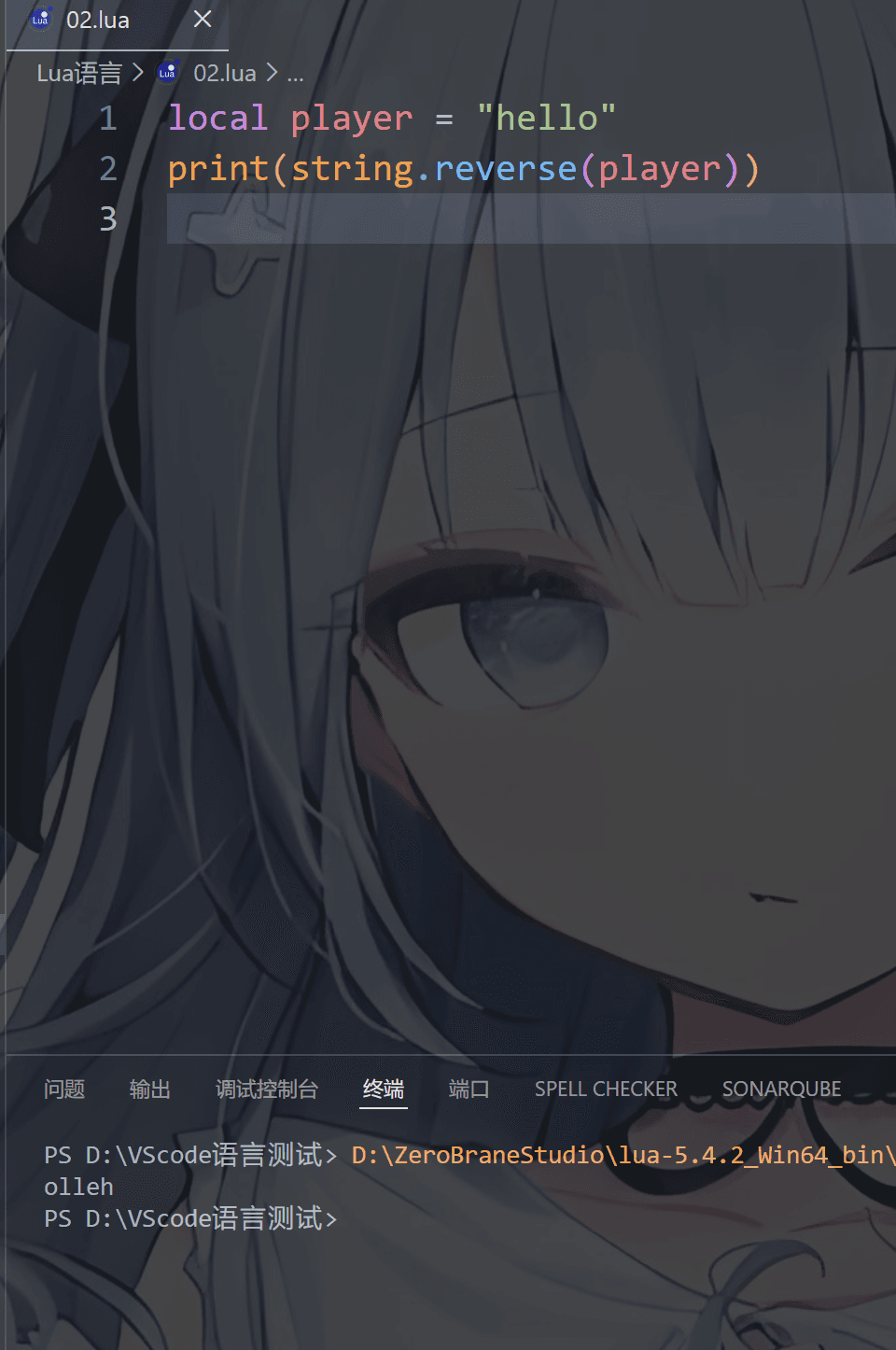
⑤ 字符串反转(只支持ASCII符号)
1 | string.reverse() |
⑥ 字符串格式化
1 | string.format() |
这个之前说过了,和C语言printf类似,就不细说了

常用格式符:
| 符号 | 含义 |
|---|---|
| %d | 整数 |
| %f | 浮点数 |
| %s | 字符串 |
| %q | 带引号字符串 |
| %.2f | 保留两位小数 |
| %x | 十六进制 |
这里还有更多
格式字符串可能包含以下的转义码:
- %c - 接受一个数字, 并将其转化为ASCII码表中对应的字符
- %d, %i - 接受一个数字并将其转化为有符号的整数格式
- %o - 接受一个数字并将其转化为八进制数格式
- %u - 接受一个数字并将其转化为无符号整数格式
- %x - 接受一个数字并将其转化为十六进制数格式, 使用小写字母
- %X - 接受一个数字并将其转化为十六进制数格式, 使用大写字母
- %e - 接受一个数字并将其转化为科学记数法格式, 使用小写字母e
- %E - 接受一个数字并将其转化为科学记数法格式, 使用大写字母E
- %f - 接受一个数字并将其转化为浮点数格式
- %g(%G) - 接受一个数字并将其转化为%e(%E, 对应%G)及%f中较短的一种格式
- %q - 接受一个字符串并将其转化为可安全被Lua编译器读入的格式
- %s - 接受一个字符串并按照给定的参数格式化该字符串
不过有一个需要注意,Lua 的格式符基本结构是:
1 | %[符号][填充][对齐][宽度][.精度]类型 |
例如
1 | ① 正负符号"+"和"-" |
我们可以用来打印角色信息
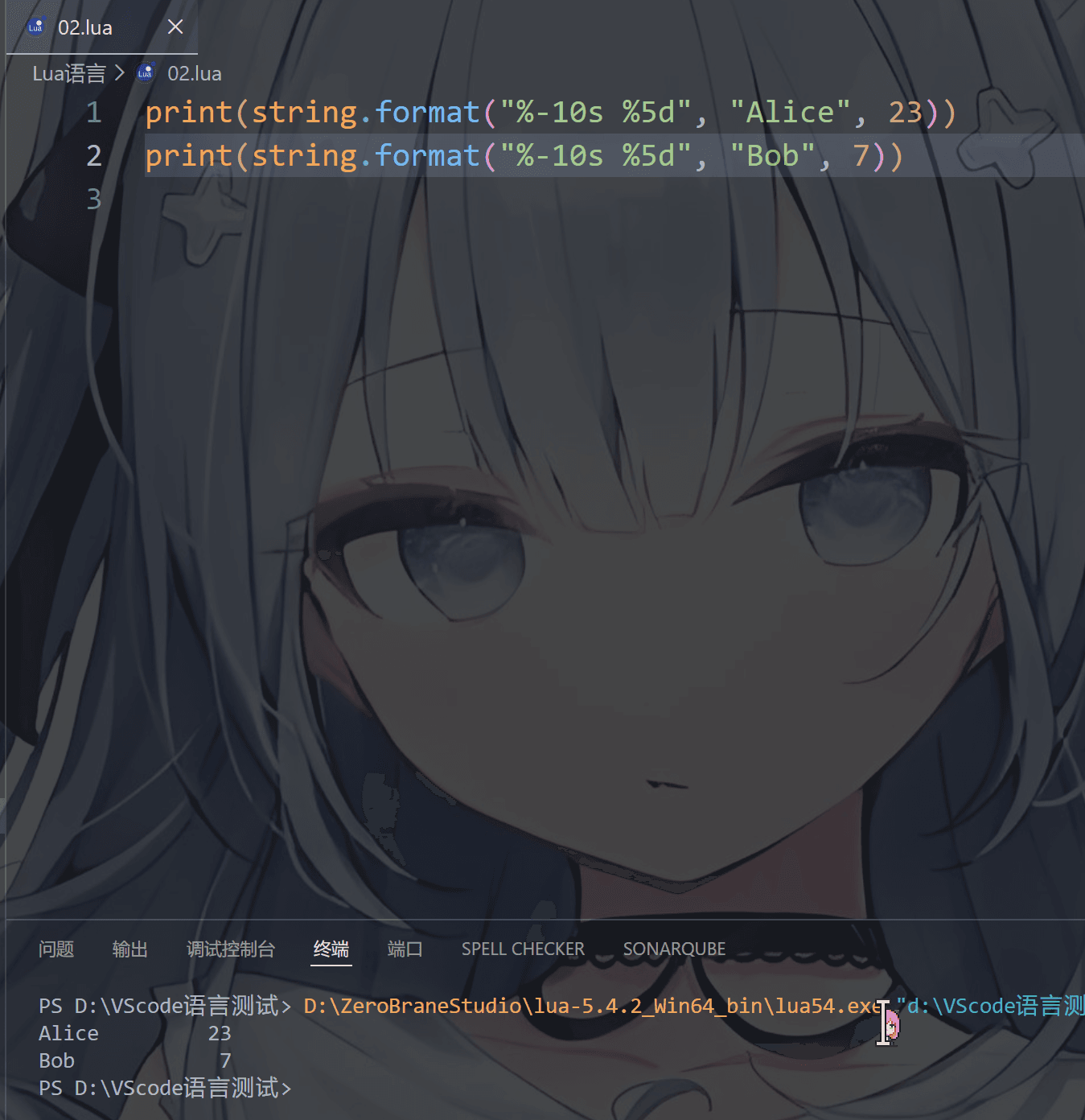
也可以输出游戏时间和评分
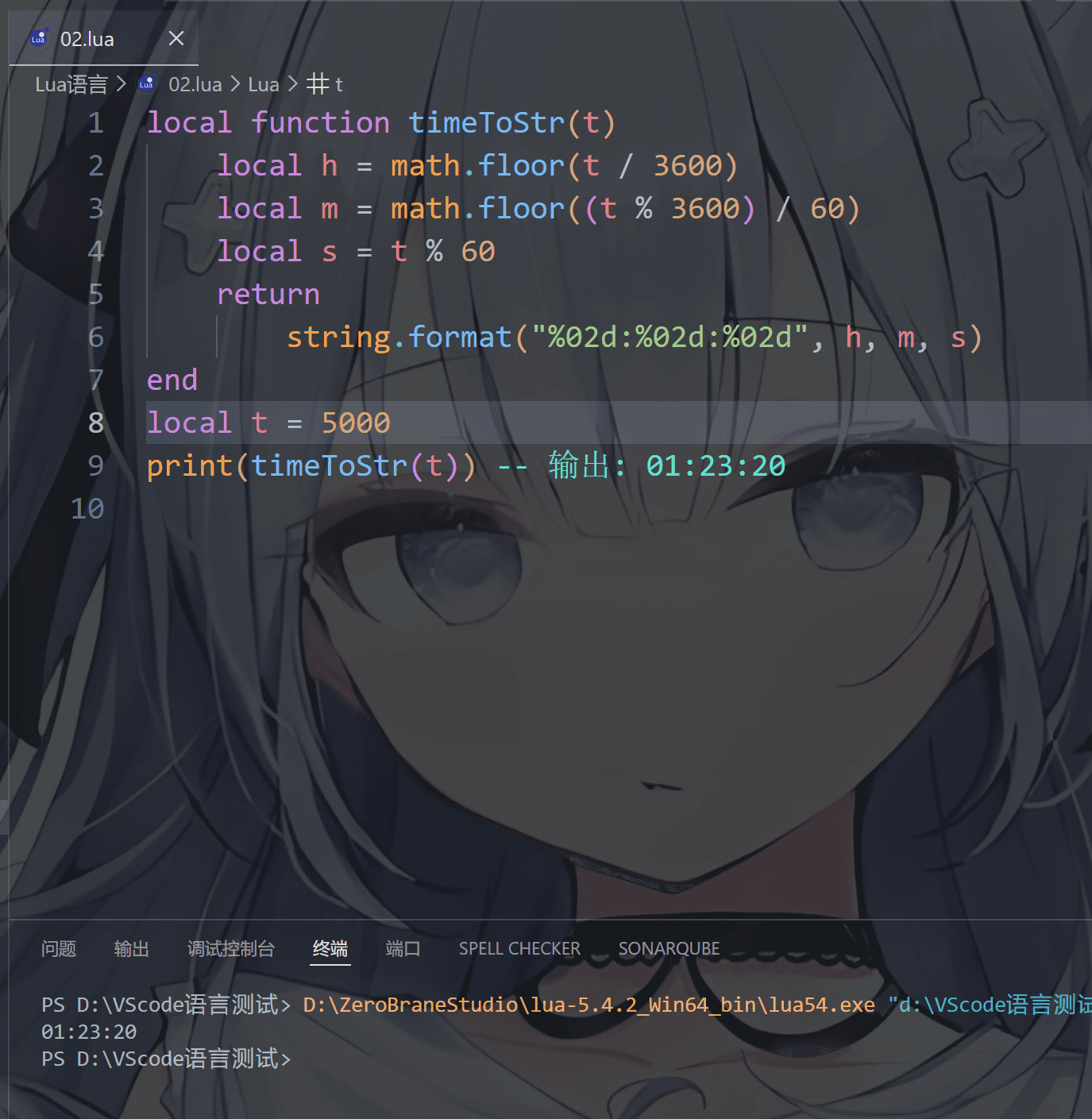
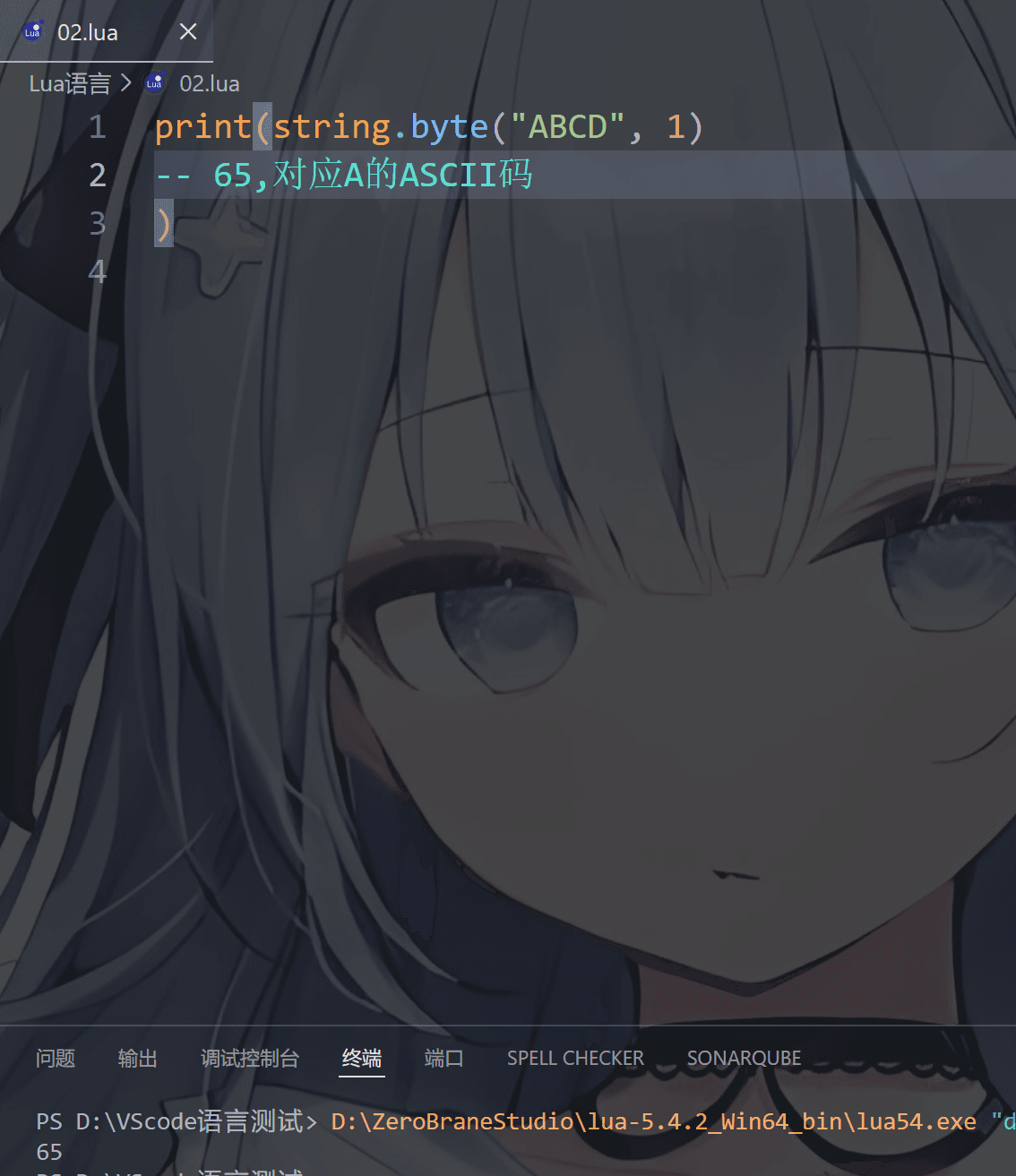
⑦ 数字和字符转换
1 | string.char() --数字 → 字符(ASCII/UTF8编码) |
char 将整型数字转成字符并连接, byte 转换字符为整数值(可以指定某个字符,默认第一个字符)

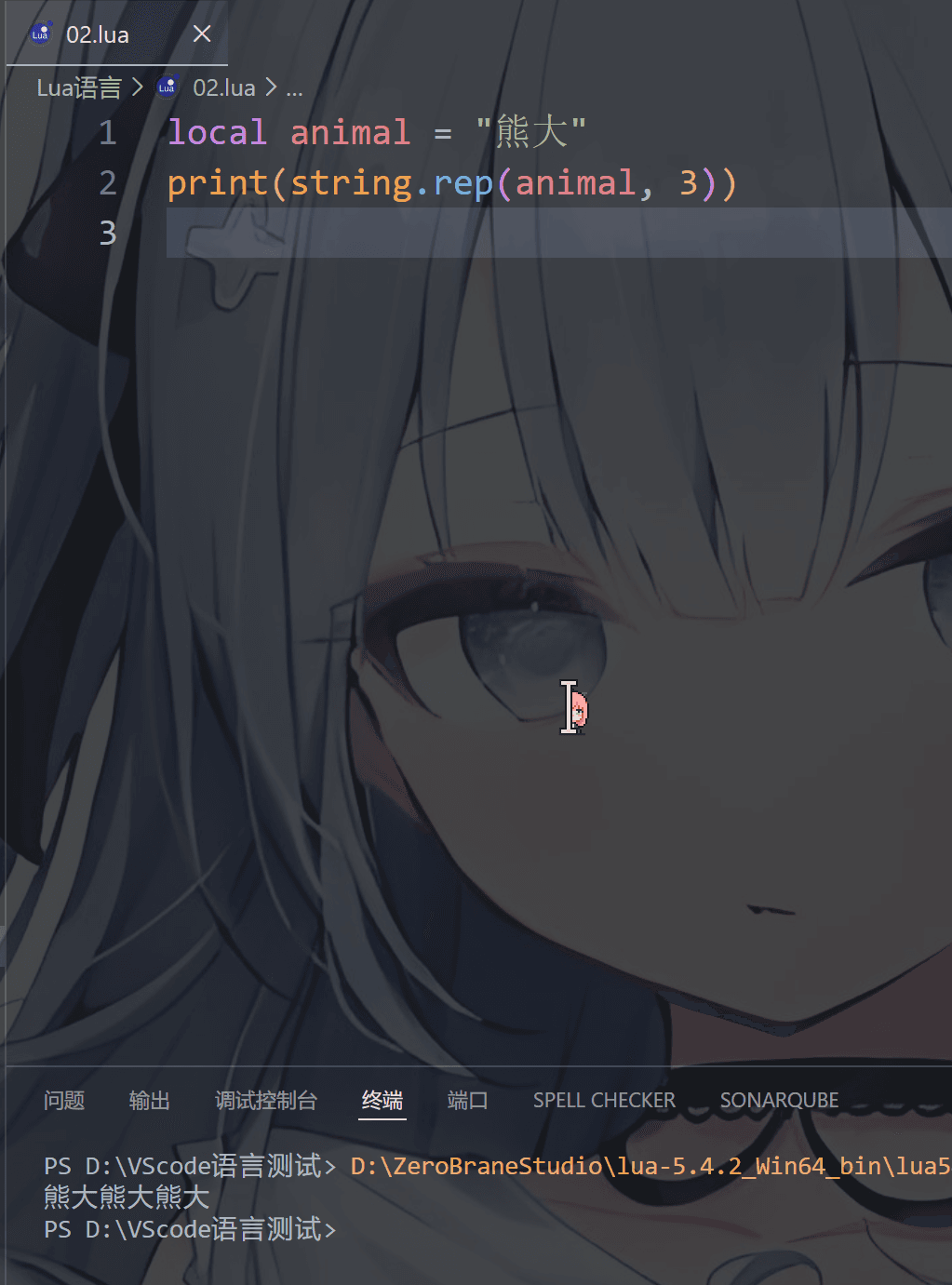
⑧ 重复字符串
1 | string.rep(string, n) |
⑨ 字符串截取
1 | string.sub(s, i, j) |
参数解释:
s:原字符串i:起始位置(必填)j:结束位置(可选,默认 -1)
你看这个和string.gsub(main, find, replace, num)是不是有点像,只不过那个是替换,这个是截取
1 | print(string.sub("abcdef", 1, 3)) |
对了,之前忘记说了,lua支持负数索引,这个特点大多数语言都不具备,负数索引就是从后往前数
1 | print(string.sub("abcdef", -1)) |
⚠️只支持ASCII符号,中文的话需要自己计算字节长度来确定其实和终止位置,因为中文是三字节,英文和数字默认1字节,而且超过范围lua不会报错
这个可以这么用
1 | ✅ 截取文件后缀名 |
⑩ 全局匹配 (循环扫描)
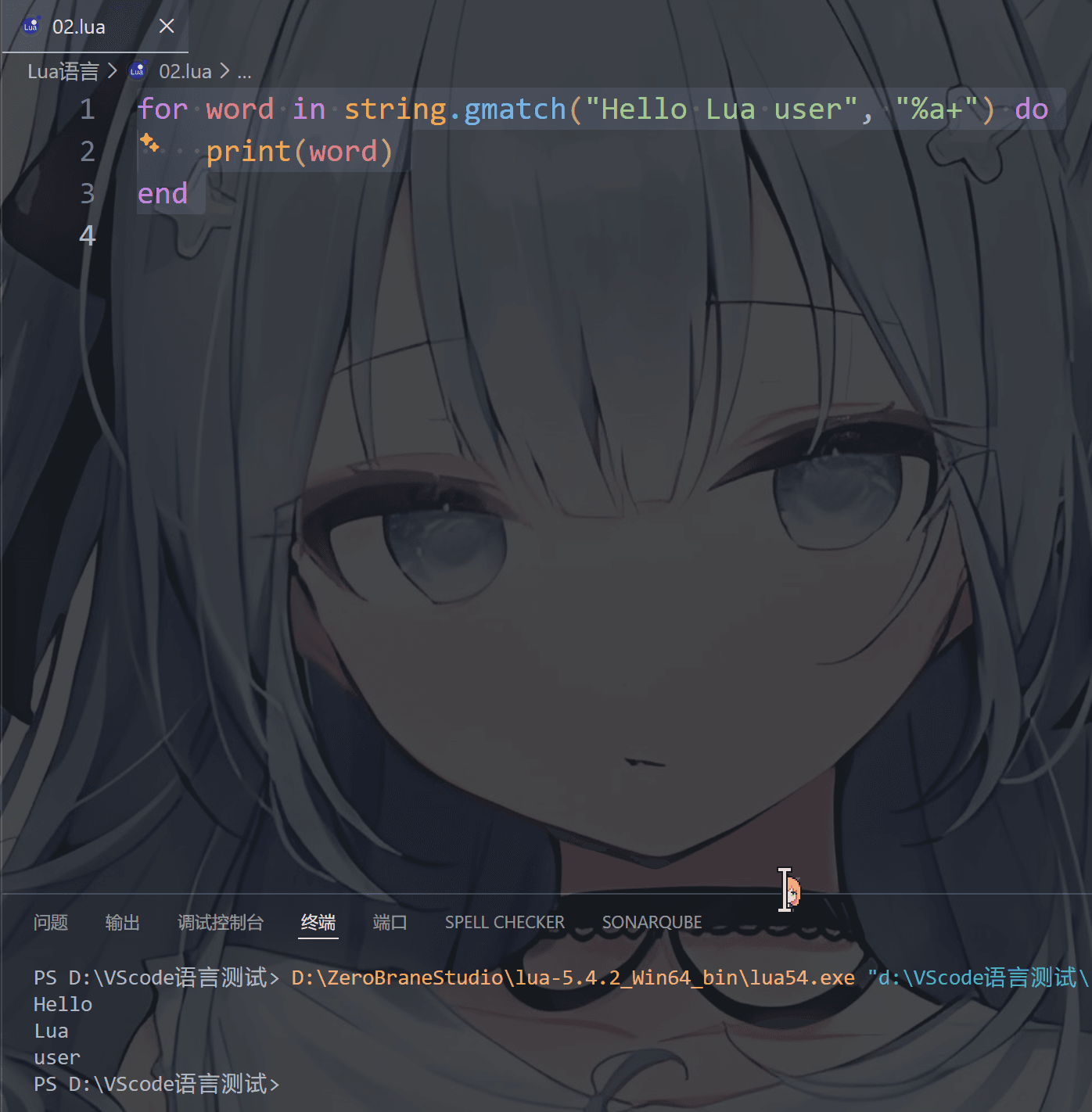
1 | string.gmatch(str, pattern) |
返回一个迭代器函数,每一次调用这个函数,返回一个在字符串 str 找到的下一个符合 pattern 描述的子串。如果参数 pattern 描述的字符串没有找到,迭代函数返回nil ,通常和 for 一起用
说人话就是找到所有匹配条件的东西,比如下方这个就是找到字符串里的所有英文单词
这些是可以互相组合的,例如
1 | for word in string.gmatch("Hello Lua user", "%a+") do |
⑪ 首次匹配 (单次扫描)
1 | string.match(str, pattern, init) |
参数含义:
- str : 要匹配的字符串
- pattern: 模式(规则)
- init : 从第几个字符开始匹配(可选),默认1
1 | print(string.match("abc123def456", "%d+", 7)) |
区别
gmatch = 找“所有符合规则的东西”(循环),全局匹配(一个一个返回)
match = 找“第一个符合规则的东西”(一次),只匹配第一个结果(一次性返回)
注意是match是每个捕获都会返回第一个匹配结果,不是只返回一个结果
有关pattern知识(这里用string.match来讲)
Lua 没有完整正则表达式,但有一套“轻量正则”(pattern)
可以理解为:
Lua pattern = 简化版正则表达式
模式:
(1)基本字符类
| 模式 | 含义 | 示例 |
|---|---|---|
| %a | 字母 (A-Z a-z) | “abc” |
| %d | 数字 (0-9) | “123” |
| %l | 小写字母 | “abc” |
| %u | 大写字母 | “ABC” |
| %w | 字母或数字 | “abc123” |
| %s | 空白字符 | 空格、tab |
| %p | 标点符号 | . , ! ? |
| %c | 控制字符 | \n \t |
| %x | 十六进制 | 0-9 A-F |
| %z | 字符 0 | \0 |
‘%’ 用作特殊字符的转义字符,因此 ‘%.’ 匹配点;’%%’ 匹配字符 ‘%’
转义字符 ‘%’不仅可以用来转义特殊字符,还可以用于所有的非字母的字符
例如
1 | print(string.match("abc1234", "%a+")) |

(2)取反(大写字母)
| 模式 | 含义 |
|---|---|
| %A | 非字母 |
| %D | 非数字 |
| %S | 非空白 |
| %W | 非字母数字 |
例如
1 | string.match("abc123", "%D+") |
(3)普通字符匹配
| 模式 | 含义 |
|---|---|
| a | 字符 a |
| 1 | 字符 1 |
| Lua | 字符串 Lua |
1 | string.match("Hello Lua", "Lua") |
(4)特殊符号(量词)
| 符号 | 含义 |
|---|---|
| . | 任意字符 |
| + | 1次或多次 |
| * | 0次或多次 |
| - | 0次或多次(最短匹配) |
| ? | 0次或1次 |
1 | . 任意字符 |
* = 贪婪- = 非贪婪
(5)字符集合 [ ]
类似正则的字符集
例如[abc] 表示a 或 b 或 c,那么[ ^ abc ]表示除了abc以外的的字符

范围为
- [a-z]
- [0-9]
- [A-Z]
1 | string.match("abc123", "[0-9]+") |
(6)边界符(锚点)
首先我们需要清楚一件事—–那就是边界符匹配的是位置,也就是边界,而不是字符
| 模式 | 含义 |
|---|---|
| ^ | 字符串开头,即字符串开始边界 |
| $ | 字符串结尾,即字符串结束边界 |
| %f[set] | 前沿边界(Lua 独有),即“自定义边界” |
1 | ^ 开头匹配 |
可以看出,hello位于字符串的开头,匹配成功,而world位于字符串的末尾,匹配不成功
1 | $ 结尾匹配 |
其中^和$这两个一看就明白是干嘛的, ^是从从字符串开头找有没有这个
$是从字符串结尾找有没有这个
重点就是这个%f比较难理解
%f = frontier = 边界,指的是匹配“字符边界”,不是字符本身
%f[set]匹配一个位置:
左边的字符不属于 set,右边的字符属于 set
| 部分(以%a为例) | 含义 |
|---|---|
| %f[%a] | 左边不是字母,右边是字母 |
| %f[ ^%a ] | 左边是字母,右边不是字母 |
我们还是看具体的例子吧
1 | --例一:匹配单词开头 |
| 边界符 | 含义 | 可自定义 | 示例 |
|---|---|---|---|
^ |
字符串开始 | ❌ | "^hello" |
$ |
字符串结束 | ❌ | "world$" |
%f[%w] |
单词开始 | ✅ | %f[%w]hello |
%f[^%w] |
单词结束 | ✅ | hello%f[^%w] |
%f[%d] |
数字开始 | ✅ | %f[%d]123 |
%f[^%d] |
数字结束 | ✅ | %f[^%d]123 |
%f[%a] |
字母开始 | ✅ | %f[%a]abc |
%f[^%a] |
字母结束 | ✅ | %f[^%a]abc |
%f[b] |
字母 b 开始 | ✅ | %f[b]abc |
%f[^b] |
字母 b 结束 | ✅ | %f[^b]abc |
我们可以使用更多例子来解释这个东西,记住%f[%a]这种只是代表位置相当于一个索引号不是具体的数字或者字母
我们以后看见这个%f[%a]心里可以默认这是单词的开头可以直接忽视,因为这个是代表我们看不见的东西的属于概念
1 | --例一: 单词的匹配 |
%f 除了可以获取看的见的东西,还能获取看不见的东西—-位置
也就是使用 %f[ set] ()
它的作用是:精确获取某个“边界位置”的索引,当然这里表示获取某类字符开始的位置
因为:
%f只匹配 位置()捕获 当前位置的索引
对了,你们看到的()这种括号表示捕获,也就是我们下面要讲的东西,每个括号即每个捕获都有一个返回值
例如
1 | --例一:获取所有单词的位置 |
常见的写法和用途
不需要记住,用到时看一眼就行了,而且写法千变万化,并不局限于以下写法
| 单词边界 | 作用 |
|---|---|
%f[%a]() |
单词开始 |
%f[%A]() |
单词结束 |
| 单词提取 | 作用 |
|---|---|
%f[%a](%w+) |
提取单词 |
%f[%a]%w+%f[%A] |
完整单词 |
| 数字识别 | 作用 |
|---|---|
%f[%d]() |
数字开始 |
%f[%d]%d+ |
提取整数 |
%f[%d]%d+%.%d+ |
浮点数 |
Lua变量规则:
[ a-z A-Z_ ] [a-z A-Z 0-9_ ]*
| Lua变量名 | 作用 |
|---|---|
%f[%a_]()([%a_][%w_]*) |
变量名 + 位置 |
%f[%a_][%a_][%w_]* |
变量名 |
| 标点检测 | 作用 |
|---|---|
%f[%p]() |
标点开始 |
%p+ |
连续标点 |
| 空格边界 | 作用 |
|---|---|
%f[%s]() |
空格开始 |
%s+ |
连续空格 |
| 大写字母 | 作用 |
|---|---|
%f[%u]() |
大写字母开始 |
%f[%u][A-Z]+ |
大写单词 |
单词 + 位置
变量 + 位置
数字 + 位置
标点 + 位置
但是各位有没有想过,那么括号这种东西怎么匹配呢?
之前有一个东西忘记说了那就是
在 Lua 中,
%b是一种特殊的模式匹配字符(Pattern Matching),专门用于匹配平衡的配对符号(如成对的括号、大括号、方括号等)。它通过string.find、string.gsub等函数使用,格式为%bxy,其中x是起始字符,y是结束字符。
例如
1 | %b() 匹配 () |
更高级的用途例如
1 | --例一: 解析代码 token |
什么,你说这个玩意有什么用,说实话我目前也不知道有什么用(毕竟我才刚学),AI说这个可以写写代码高亮(非常常见),代码格式化工具,代码检查工具,DSL,模板引擎,代码转换工具,解释器 / 编程语言
但是吧,我觉得大家可能用不上这个,因为我学lua只是为了做游戏又不是写无聊的编辑器
(7)捕获(capture)
捕获组就是用括号 () 包起来的部分,空的捕获 () 将捕获到当前字符串的位置(它是一个数字)
捕获 = “把匹配到的内容抓出来”
1 | 基本捕获 () |
之所以会出现多个返回值是因为有因为有多个括号:
例如基本捕获里的
(%a+) –> 第1个捕获
(%d+) –> 第2个捕获return “abc”, “123”
8)引用捕获 %1 %2 ...
1 | string.match("hello hello", "(%w+)%s+%1") |
%1= 第一个捕获的内容
%2= 第二个捕获的内容…以此类推
我们只需要记住这些即可
| 模式 | 用途 |
|---|---|
| %d+ | 数字 |
| %a+ | 单词 |
| %w+ | 字母数字 |
| .+ | 任意 |
| .- | 最短任意 |
| ^ | 开头 |
| $ | 结尾 |
| () | 捕获 |
| [^x]+ | 非x |
转义字符
转义字符用于表示不能直接显示的字符,比如后退键,回车键等,如在字符串转换双引号可以使用 \
| 转义字符 | 意义 | ASCII码值(十进制) |
|---|---|---|
| \a | 响铃(BEL) | 007 |
| \b | 退格(BS) ,将当前位置移到前一列 | 008 |
| \f | 换页(FF),将当前位置移到下页开头 | 012 |
| \n | 换行(LF) ,将当前位置移到下一行开头 | 010 |
| \r | 回车(CR) ,将当前位置移到本行开头 | 013 |
| \t | 水平制表(HT) (跳到下一个TAB位置) | 009 |
| \v | 垂直制表(VT) | 011 |
| \ | 代表一个反斜线字符’’' | 092 |
| ' | 代表一个单引号(撇号)字符 | 039 |
| " | 代表一个双引号字符 | 034 |
| \0 | 空字符(NULL) | 000 |
| \ddd | 表示 1~3 位十进制数对应的字符 | d = 0~9 |
| \xhh | 表示 1~2 位十六进制数对应的字符 | h = 0 |
1 | 🔔 1️⃣ \a 响铃(BEL) |
1 | ⌫ 2️⃣ \b 退格(Backspace) |
1 | 📄 3️⃣ \f 换页(Form Feed) |
1 | ⏎4️⃣ \n 换行(最常用) |
1 | ↩️ 5️⃣ \r 回车(Return) |
1 | ⇥6️⃣ \t 制表符(Tab) |
1 | ⬇️ 7️⃣ \v 垂直制表(Vertical Tab) |
1 | 🔙 8️⃣ \ 反斜杠 |
1 | 🧾 9️⃣ \' 单引号 |
1 | \0 空字符(NULL) |
1 | \ddd = 用 十进制数字 表示一个字符 |
Lua 没有八进制字符转义(不像 C 语言)
但 Lua 有“八进制数字字面量”(Lua 5.3+)和“十进制/十六进制字符转义”
数字字面量(lua代码)
| 写法 | 含义 |
|---|---|
| 65 | 十进制 |
| 0x41 | 十六进制 |
| 0o101 | 八进制(Lua 5.3+) |
| 0b1000001 | 二进制(Lua 5.3+) |
最常用的 5 个转义字符:
| 转义 | 含义 |
|---|---|
| \n | 换行 |
| \t | Tab |
| \ | 反斜杠 |
| \ “ | 双引号 |
| \ ‘ | 单引号 |
进阶:
| 转义 | 用途 |
|---|---|
| \r | 回车(进度条) |
| \0 | 空字符 |
| \xhh | 十六进制字符 |
| \ddd | 八进制字符 |
[^%d]:
评论区