1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
| import os
import sys
import shutil
import zipfile
import tempfile
import re
from pathlib import Path
from markitdown import MarkItDown
IMAGE_EXTS = {'.jpg', '.jpeg', '.png', '.gif', '.webp', '.svg', '.bmp', '.tiff'}
def inject_yaml_and_save(md_content, out_md_path, assets_folder_name):
yaml_header = f"---\ntypora-copy-images-to: ./{assets_folder_name}\n---\n\n"
with open(out_md_path, 'w', encoding='utf-8') as f:
f.write(yaml_header + md_content)
def extract_and_map_ppt_images(file_path, assets_dir):
slide_images = {}
try:
with zipfile.ZipFile(file_path, 'r') as z:
for info in z.infolist():
if '/media/' in info.filename and not info.filename.endswith('/'):
img_name = Path(info.filename).name
with open(assets_dir / img_name, 'wb') as f:
f.write(z.read(info.filename))
for info in z.infolist():
if info.filename.startswith('ppt/slides/_rels/slide') and info.filename.endswith('.xml.rels'):
match = re.search(r'slide(\d+)\.xml\.rels', info.filename)
if match:
slide_num = int(match.group(1))
xml_content = z.read(info.filename).decode('utf-8', errors='ignore')
images = re.findall(r'Target="\.\./media/([^"]+)"', xml_content)
if images:
slide_images[slide_num] = images
except: pass
return slide_images
def extract_word_images(file_path, assets_dir):
images = []
try:
with zipfile.ZipFile(file_path, 'r') as z:
for info in z.infolist():
if 'word/media/' in info.filename and not info.filename.endswith('/'):
img_name = Path(info.filename).name
with open(assets_dir / img_name, 'wb') as f:
f.write(z.read(info.filename))
images.append(img_name)
except: pass
return images
def convert_single_file(file_path, base_out_dir, silent=False):
file_path = Path(file_path)
if not file_path.exists() or file_path.suffix.lower() in ['.zip', '.doc', '.ppt', '.xls']:
return False
base_name = file_path.stem
ext = file_path.suffix.lower()
wrapper_dir = Path(base_out_dir) / base_name
wrapper_dir.mkdir(parents=True, exist_ok=True)
assets_folder_name = f"{base_name}_assets"
assets_dir = wrapper_dir / assets_folder_name
assets_dir.mkdir(parents=True, exist_ok=True)
ppt_slide_images = {}
word_images = []
if ext == '.pptx':
ppt_slide_images = extract_and_map_ppt_images(file_path, assets_dir)
elif ext == '.docx':
word_images = extract_word_images(file_path, assets_dir)
if not silent:
print(f" 🔄 正在解析: {file_path.name} ...")
try:
md = MarkItDown()
result = md.convert(str(file_path))
md_content = result.text_content if result else ""
except Exception as e:
print(f" ❌ {file_path.name} 转换失败: {e}")
return False
md_content = re.sub(r'!\[.*?\]\(data:image/[^;]+;base64,[^\)]+\)', '', md_content)
if ext == '.pdf':
md_content = "> ⚠️ **注意**:PDF 格式目前仅支持文本提取,图片不可提取。\n\n" + md_content
if ext == '.pptx' and ppt_slide_images:
lines = md_content.split('\n')
new_lines = []
for line in lines:
new_lines.append(line)
match = re.search(r'<!-- Slide number: (\d+) -->', line)
if match:
slide_num = int(match.group(1))
if slide_num in ppt_slide_images:
new_lines.append("\n> 📎 **本页附图**:")
for img in ppt_slide_images[slide_num]:
new_lines.append(f"")
new_lines.append("\n---")
md_content = '\n'.join(new_lines)
if ext == '.docx' and word_images:
md_content += "\n\n---\n### 📎 文档提取的附图资源\n"
for img in word_images:
md_content += f"\n\n"
out_md_path = wrapper_dir / f"{base_name}.md"
inject_yaml_and_save(md_content, out_md_path, assets_folder_name)
return True
def convert_merged_images(image_paths, base_out_dir, folder_name="新建文件"):
if not image_paths: return False
wrapper_dir = Path(base_out_dir) / folder_name
wrapper_dir.mkdir(parents=True, exist_ok=True)
assets_folder_name = f"{folder_name}_assets"
assets_dir = wrapper_dir / assets_folder_name
assets_dir.mkdir(parents=True, exist_ok=True)
md_lines = []
for img in image_paths:
img = Path(img)
shutil.copy(img, assets_dir)
md_lines.append(f"\n")
out_md_path = wrapper_dir / f"{folder_name}.md"
inject_yaml_and_save("\n".join(md_lines), out_md_path, assets_folder_name)
return True
def process_zip_depth1(zip_path, base_out_dir):
zip_path = Path(zip_path)
zip_wrapper_dir = Path(base_out_dir) / zip_path.stem
temp_dir = Path(tempfile.mkdtemp())
with zipfile.ZipFile(zip_path, 'r') as z:
depth1_infos = [info for info in z.infolist() if not info.is_dir() and '/' not in info.filename]
if not depth1_infos:
print(f"\n 👀 ZIP包 [{zip_path.name}] 的根目录没有发现文件,已跳过。")
shutil.rmtree(temp_dir, ignore_errors=True)
return
file_names = [info.filename for info in depth1_infos]
print(f"\n 📦 已检测到 ZIP [{zip_path.name}] 深度 1 包含以下文件:\n - " + "\n - ".join(file_names))
zip_wrapper_dir.mkdir(parents=True, exist_ok=True)
images_to_merge = []
regular_converted = []
for info in depth1_infos:
extracted_path = z.extract(info, path=temp_dir)
if Path(extracted_path).suffix.lower() in IMAGE_EXTS:
images_to_merge.append(extracted_path)
else:
if convert_single_file(extracted_path, zip_wrapper_dir, silent=True):
regular_converted.append(info.filename)
if regular_converted:
print(f" ✅ ZIP 内已成功转换为以下文件:\n - " + "\n - ".join(regular_converted))
if images_to_merge:
convert_merged_images(images_to_merge, zip_wrapper_dir, "新建文件")
img_names = [Path(p).name for p in images_to_merge]
print(f" ✅ ZIP 内已将以下图片合并为 [新建文件.md]:\n - " + "\n - ".join(img_names))
shutil.rmtree(temp_dir, ignore_errors=True)
def main():
if len(sys.argv) < 3: return
mode = sys.argv[1]
target = sys.argv[2]
out_dir = sys.argv[3] if len(sys.argv) > 3 else "output"
if mode == "single":
if target.lower().endswith('.zip'):
process_zip_depth1(target, out_dir)
else:
if convert_single_file(target, out_dir):
print(f" ✅ 已成功转换: {Path(target).name}")
elif mode == "batch_images":
cat_name = sys.argv[5] if len(sys.argv) > 5 else "图片"
input_dir = Path(target)
images = [f for f in input_dir.iterdir() if f.suffix.lower() in IMAGE_EXTS and f.is_file()]
if not images:
print(f"\n 👀 未检测到 {cat_name} 格式的文件!")
return
print(f"\n ✨ 发现 {len(images)} 张图片,正在合并...")
if convert_merged_images(images, out_dir, "新建文件"):
img_names = [img.name for img in images]
print(f" ✅ 已将以下图片合并为 [新建文件.md]:\n - " + "\n - ".join(img_names))
elif mode == "batch":
input_dir = Path(target)
category_exts = sys.argv[4].split(',') if len(sys.argv) > 4 else []
cat_name = sys.argv[5] if len(sys.argv) > 5 else "指定"
valid_files = [f for f in input_dir.iterdir() if f.is_file() and f.suffix.lower() in category_exts]
if not valid_files:
print(f"\n 👀 未检测到 {cat_name} 格式的文件!")
return
print(f"\n ✨ 发现 {len(valid_files)} 个 {cat_name} 文件,开始施法...")
converted_files = []
for f in valid_files:
if f.suffix.lower() == '.zip':
process_zip_depth1(f, out_dir)
else:
if convert_single_file(f, out_dir):
converted_files.append(f.name)
if converted_files:
print(f"\n ✅ 已成功转换以下文件:\n - " + "\n - ".join(converted_files))
if __name__ == "__main__": main()
|

 但是我在使用起来十分的恶心,虽然官方说这是给AI用的,但是就不能给一个人类能用的吗真的是,好歹我还觉得这个东西还挺新奇的
但是我在使用起来十分的恶心,虽然官方说这是给AI用的,但是就不能给一个人类能用的吗真的是,好歹我还觉得这个东西还挺新奇的
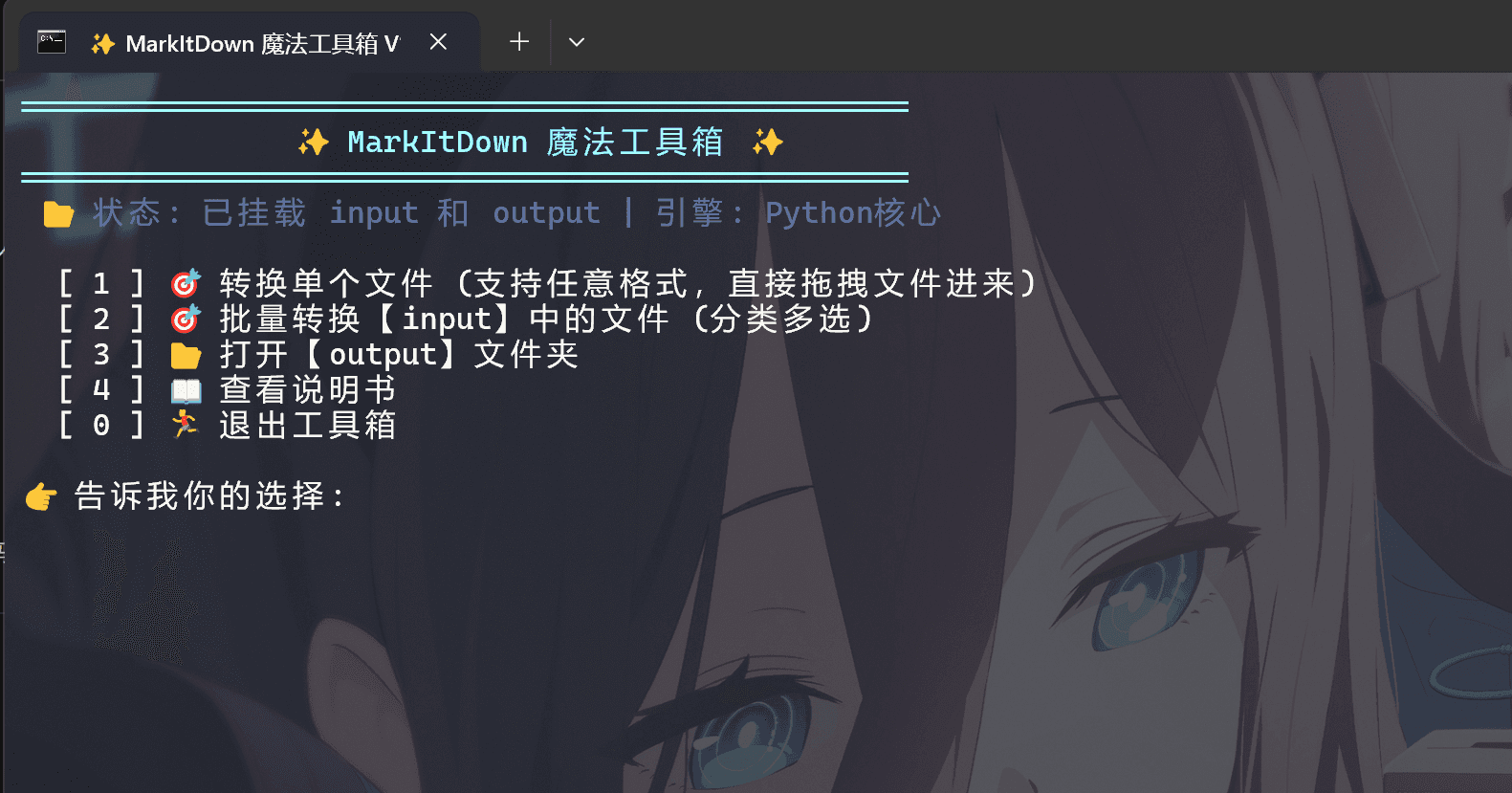
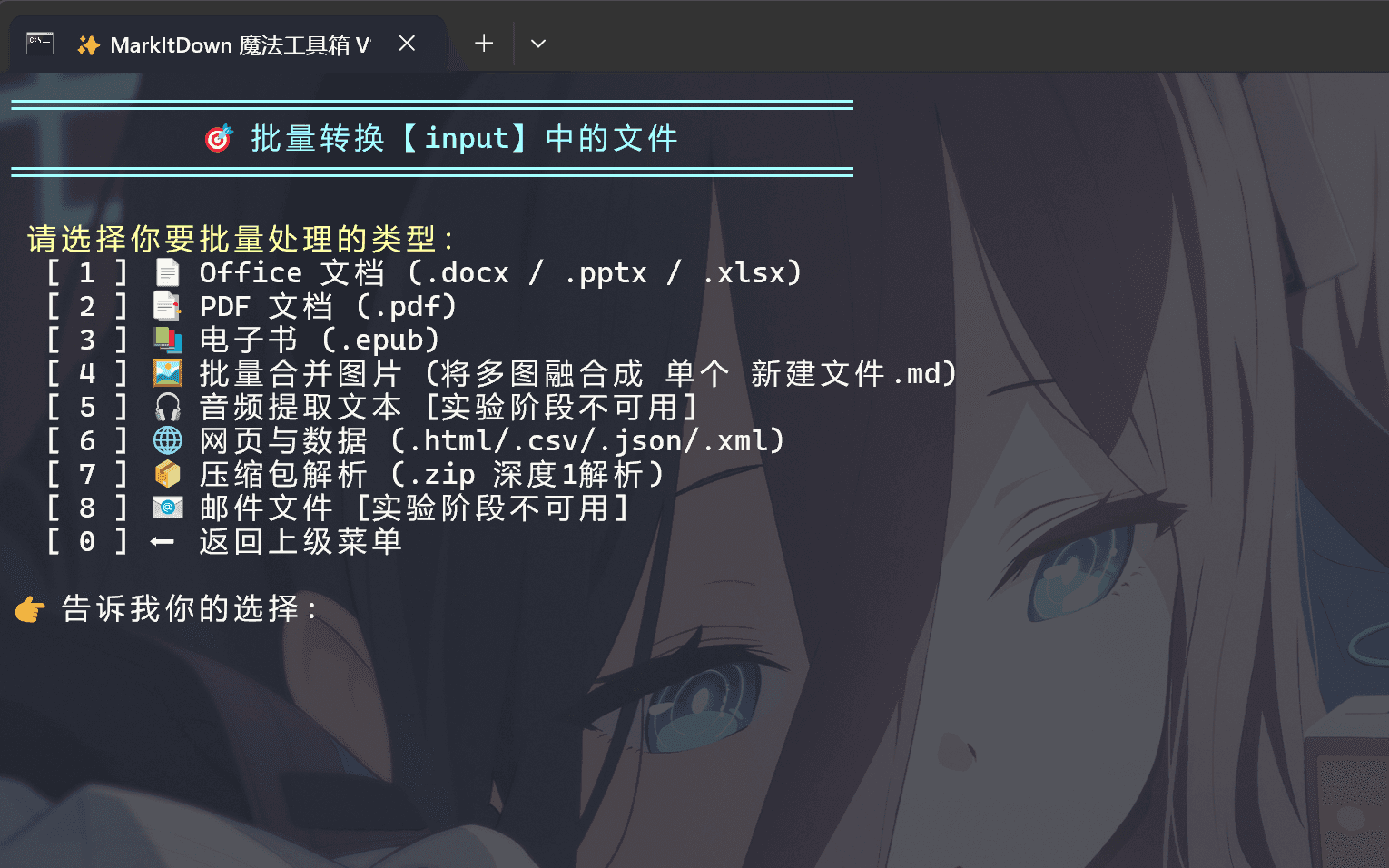
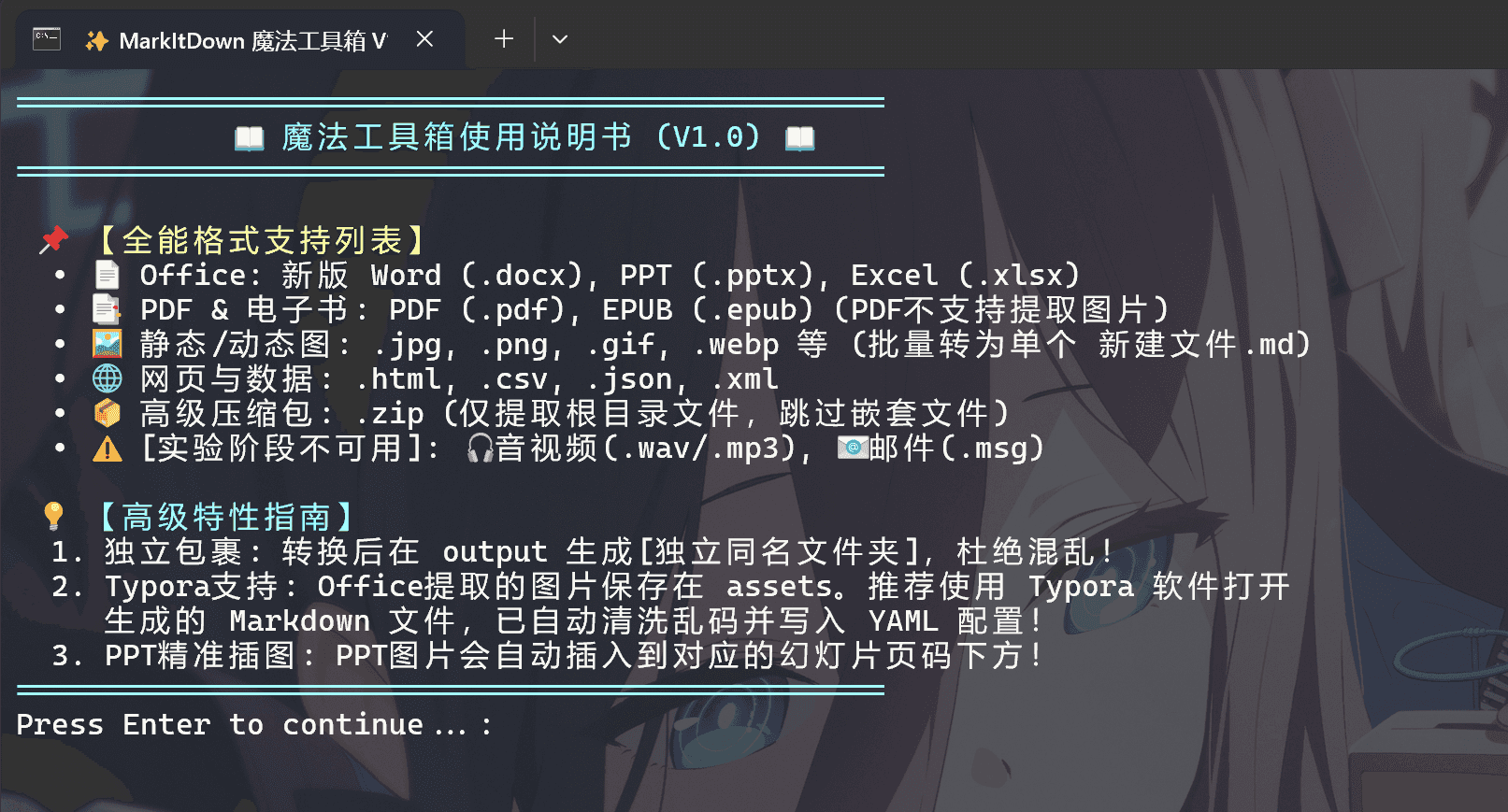
评论区