
我们来接着上一节数据库的学习
SQL的分类
二 : DML

① 添加数据

1 | 指定字段: |
注意:

如指定字段添加数据
1 | insert into employee (workno, name, gender, age, idcard, entrydate, username) values ('1001', 'Alice', 'F', 30, 'ID123456', '2020-01-15', 'alice01'); |

以及给全部字段添加数据
1 | insert into employee values ('1001', 'Alice', 'F', 30, 'ID123456', '2020-01-15', 'alice01'); |
以及批量添加数据
1 | insert into employee (workno, name, gender, age, idcard, entrydate, username) values ('1001', 'Alice', 'F', 30, 'ID123456', '2020-01-15', 'alice01'),('1002', 'Bob', 'M', 35, 'ID234567', '2019-03-22', 'bob02'), ('1003', 'Charlie', 'M', 28, 'ID345678', '2021-07-30', 'charlie03'); |
1 | insert into employee values ('1001', 'Alice', 'F', 30, 'ID123456', '2020-01-15', 'alice01'),('1002', 'Bob', 'M', 35, 'ID234567', '2019-03-22', 'bob02'), ('1003', 'Charlie', 'M', 28, 'ID345678', '2021-07-30', 'charlie03'); |

② 修改数据

1 | 修改数据: |
例如
1 | # 修改workno为1d 数据,将name改为小明 |

1 | # 修改workno为1001的数据,将name改为小红,gerder改为女 |

1 | # 将所有员工的入职日期改为2020-01-01 |

③ 删除数据

1 | delete from employee where gender = '女'; |
可以看到 小红被删除了
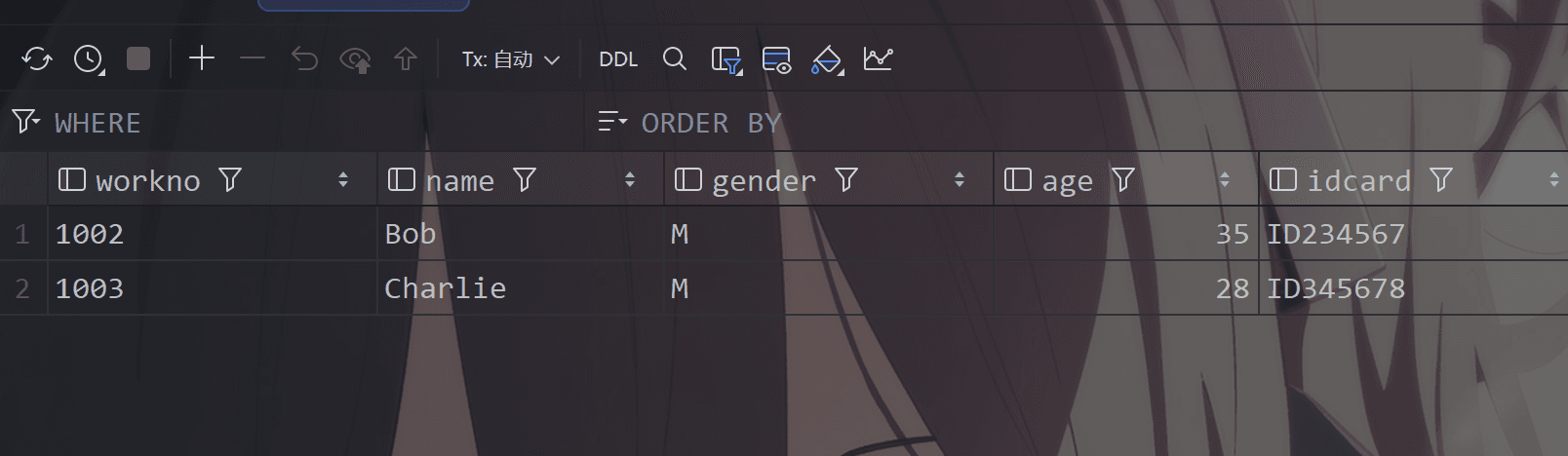
或者删除所有员工的信息
1 | delete from employee; |
可以看到都没有了
三 : DQL


1 | SELECT |
① 基本查询

首先我们创建一个表
1 | create table emp( |

1 | insert into emp (id, workno, name, gender, age, idcard, workaddress, entrydate) |

① 查询多个字段:
1 | #查询多个字段: |
我们输入
1 | # 查询指定字段name workno age 返回 |
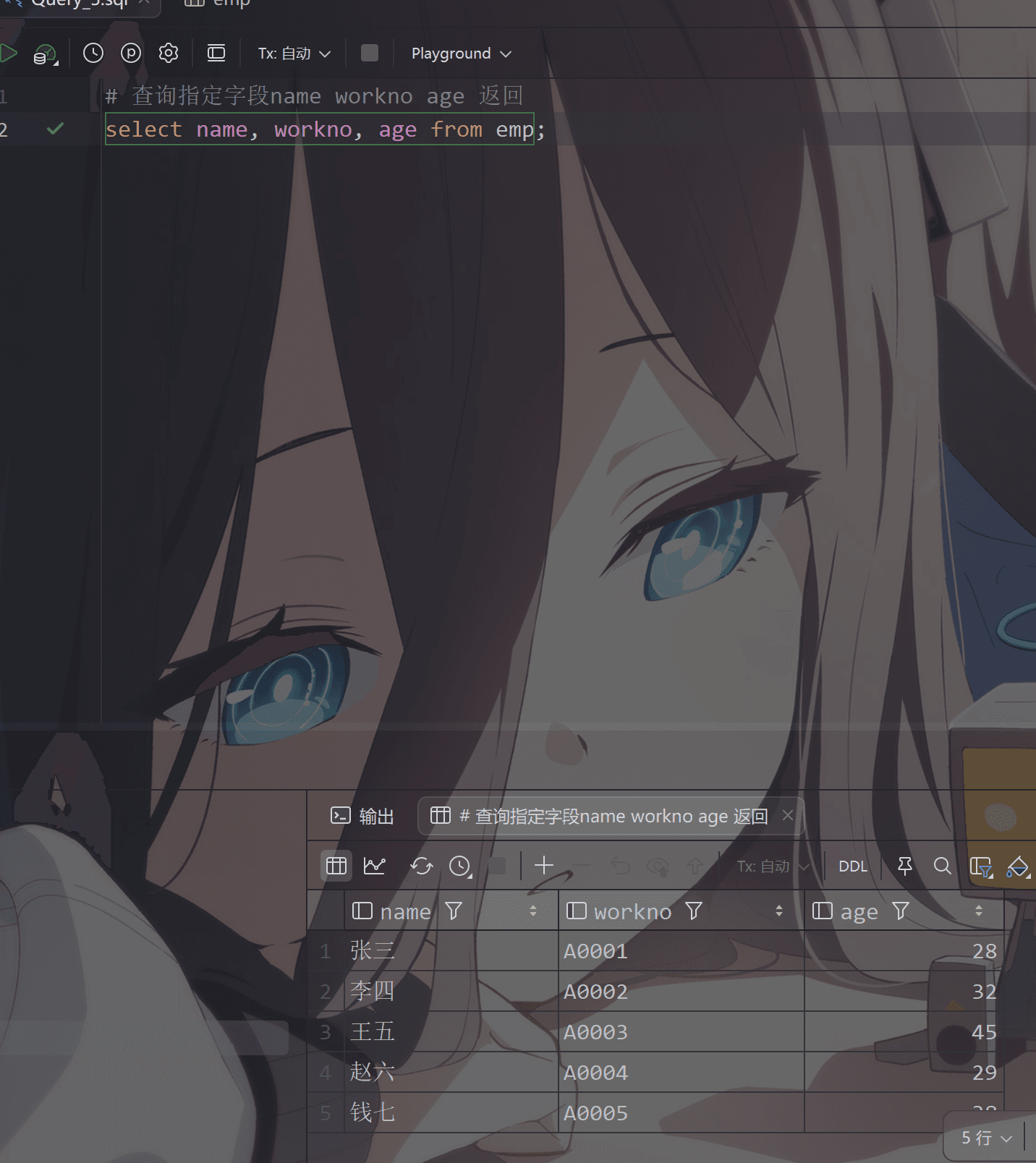
1 | # 查询所有字段返回 |

② 设置别名:
1 | #设置别名: |
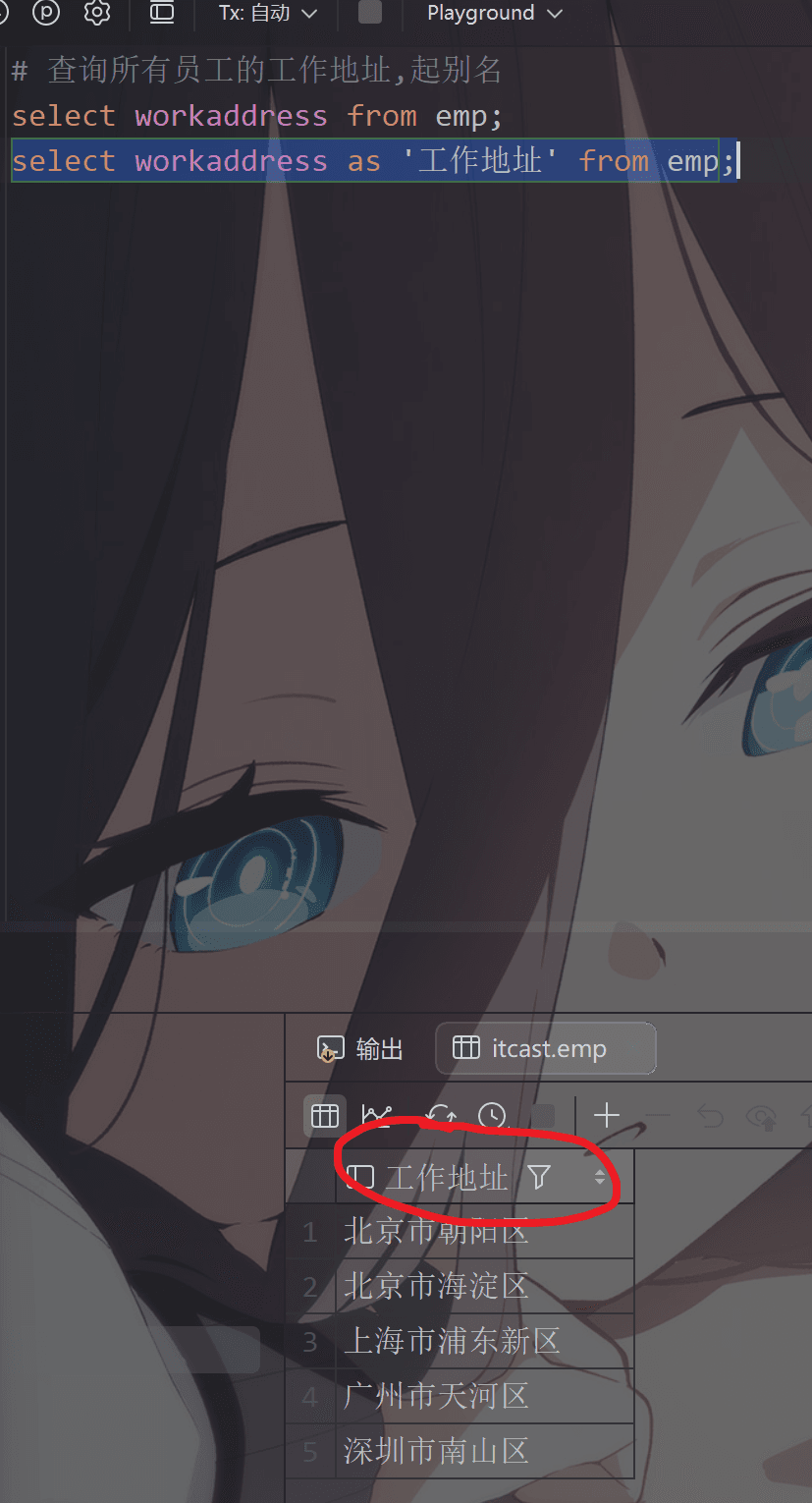
1 | # 查询所有员工的工作地址,起别名 |

可以看到名字变成了这个
③ 去除重复记录:
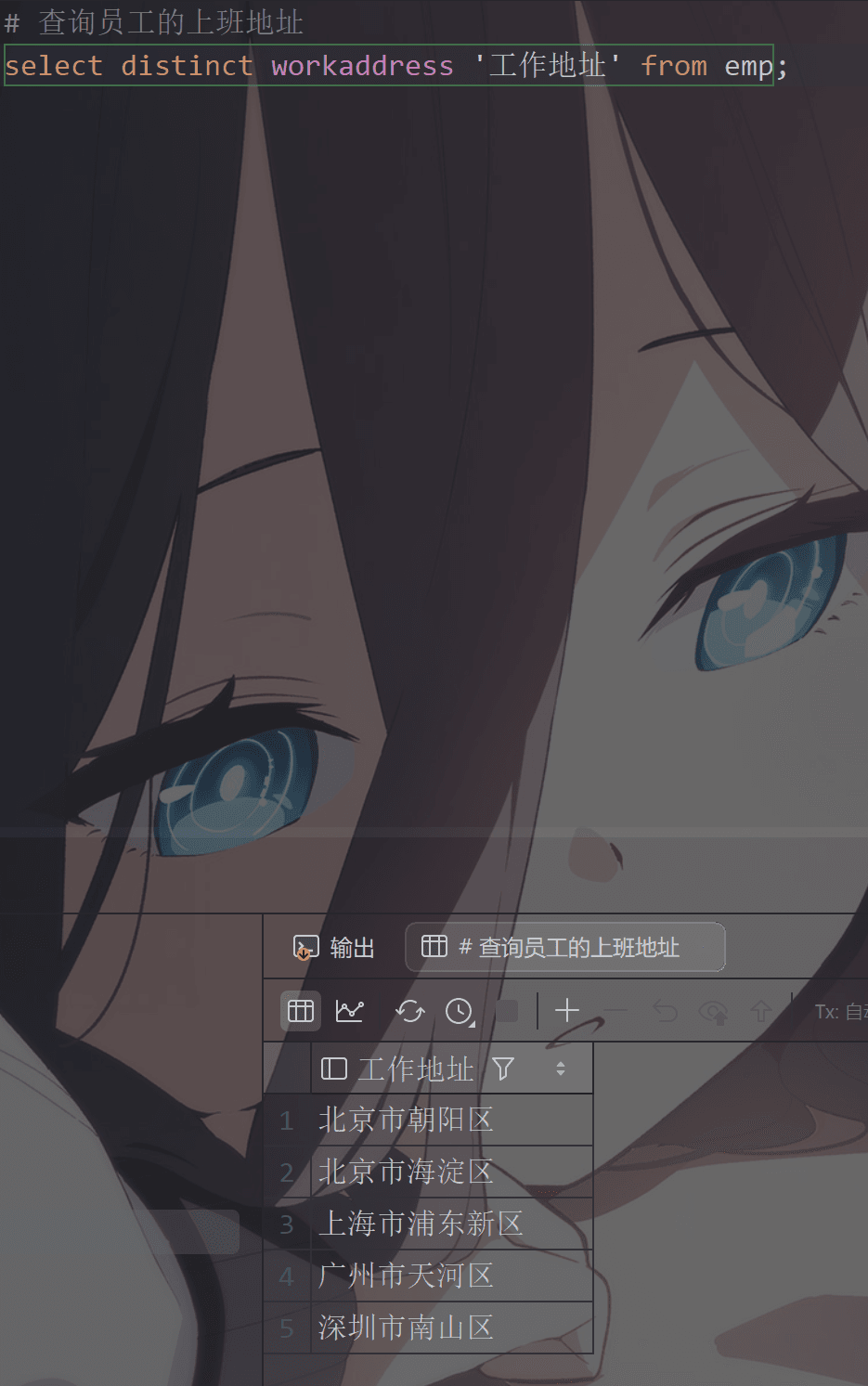
1 | #去除重复记录: |
1 | # 查询员工的上班地址 |
② 条件查询

1 | #语法: |
条件:
| 比较运算符 | 功能 |
|---|---|
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| = | 等于 |
| <> 或 != | 不等于 |
| BETWEEN … AND … | 在某个范围内(含最小、最大值) |
| IN(…) | 在in之后的列表中的值,多选一 |
| LIKE 占位符 | 模糊匹配(_匹配单个字符,%匹配任意个字符) |
| IS NULL | 是NULL |
| 逻辑运算符 | 功能 |
|---|---|
| AND 或 && | 并且(多个条件同时成立) |
| OR 或 || | 或者(多个条件任意一个成立) |
| NOT 或 ! | 非,不是 |
一下是一些练习
1 “=” 等于号
查询年龄等于28的员工
1 | # 查询年龄等于28的员工 |
2 “<” 小于号
1 | # 查询年龄小于40的员工 |
3 “<=”小于等于号
1 | # 查询年龄小于40的员工 |
4 “is null”判断是否为空
这个我们先把其中一个员工的身份证信息设置null
1 | update emp set idcard =null where name = '张三'; |
1 | # 查询没有身份证号的员工信息 |
5 “is not null”判断是否不为空
1 | # 查询有身份证号的员工信息 |
6 “!= ”和“<>”不等于号(非)
1 | # 查询有身份证号的员工信息 |
7 “and”和“&&”和 “between…and” 并列条件(与)
1 | #查询年龄28岁(包含)到40岁(包含)之间的员工信息 |
1 | #查询性别为 F 年龄小于40的员工信息 |
8 “or”和“||” 和“in(…)” 存在条件(或)
1 | #查询年龄等于28 或 32 或 45的员工信息 |
9 “like” 模糊匹配
1 | #查询姓名为两个字的员工信息 |
1 | #查询身份证号最后一位是7的员工的信息 |
③ 聚合函数

常见聚合函数:
| 函数 | 功能 |
|---|---|
| count | 统计数量 |
| max | 最大值 |
| min | 最小值 |
| avg | 平均值 |
| sum | 求和 |
1 | #语法: |
1 - count 统计数量
1 | #统计所有员工的数量 |
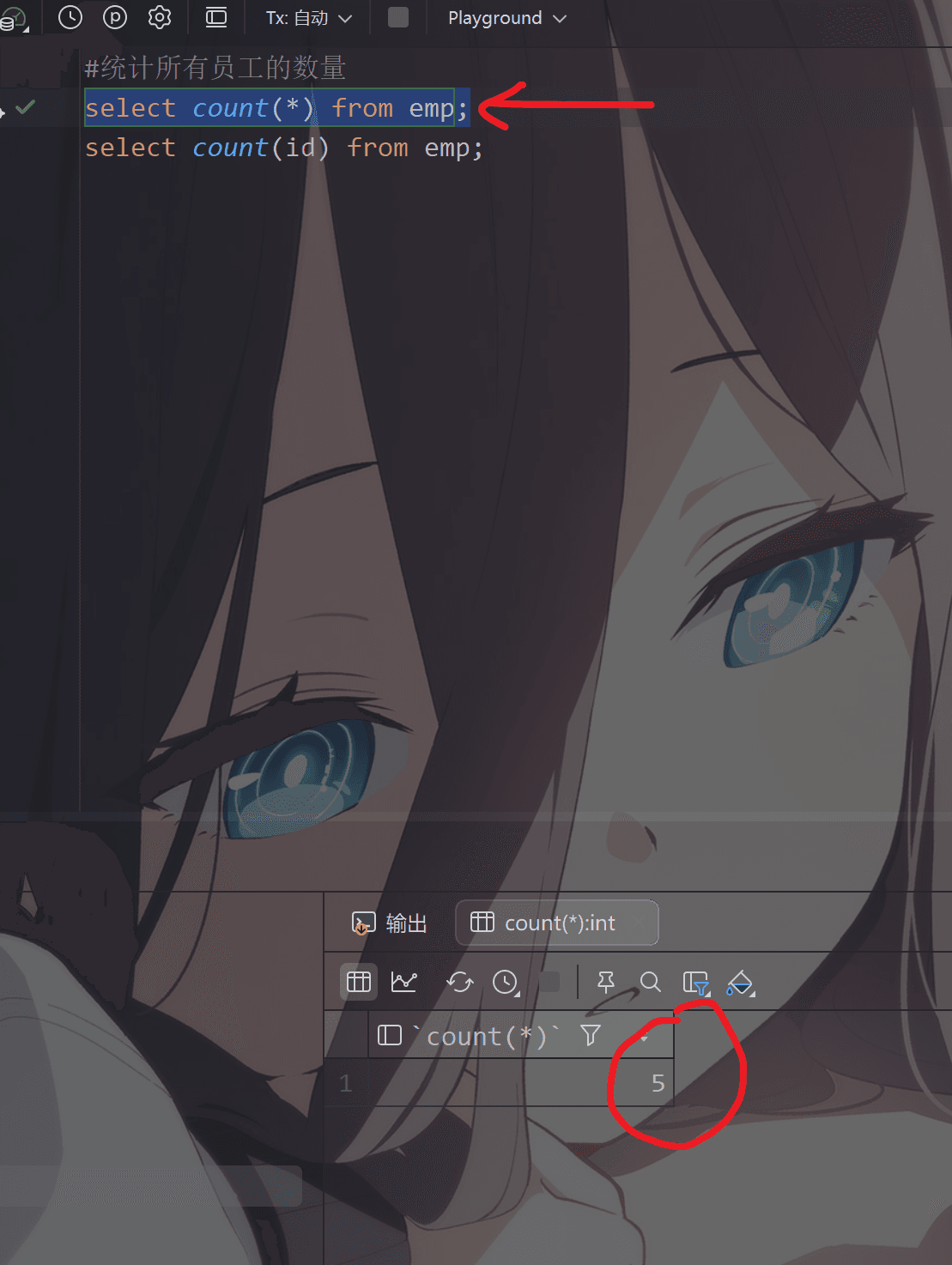
注意:

2 - max 最大值
1 | #找出年龄最大者 |
3 - min 最小值
1 | #找出年龄最小者 |
4 - avg 平均值
1 | #找出年龄平均值 |
5 - sum 求和
1 | #对年龄进行求和 |
④ 分组查询

1 | #语法: |
1 | #根据性别分组,统计男性员工和女性员工的数量 |

1 | #根据性别分组,统计男性员工和女性员工的数量 |

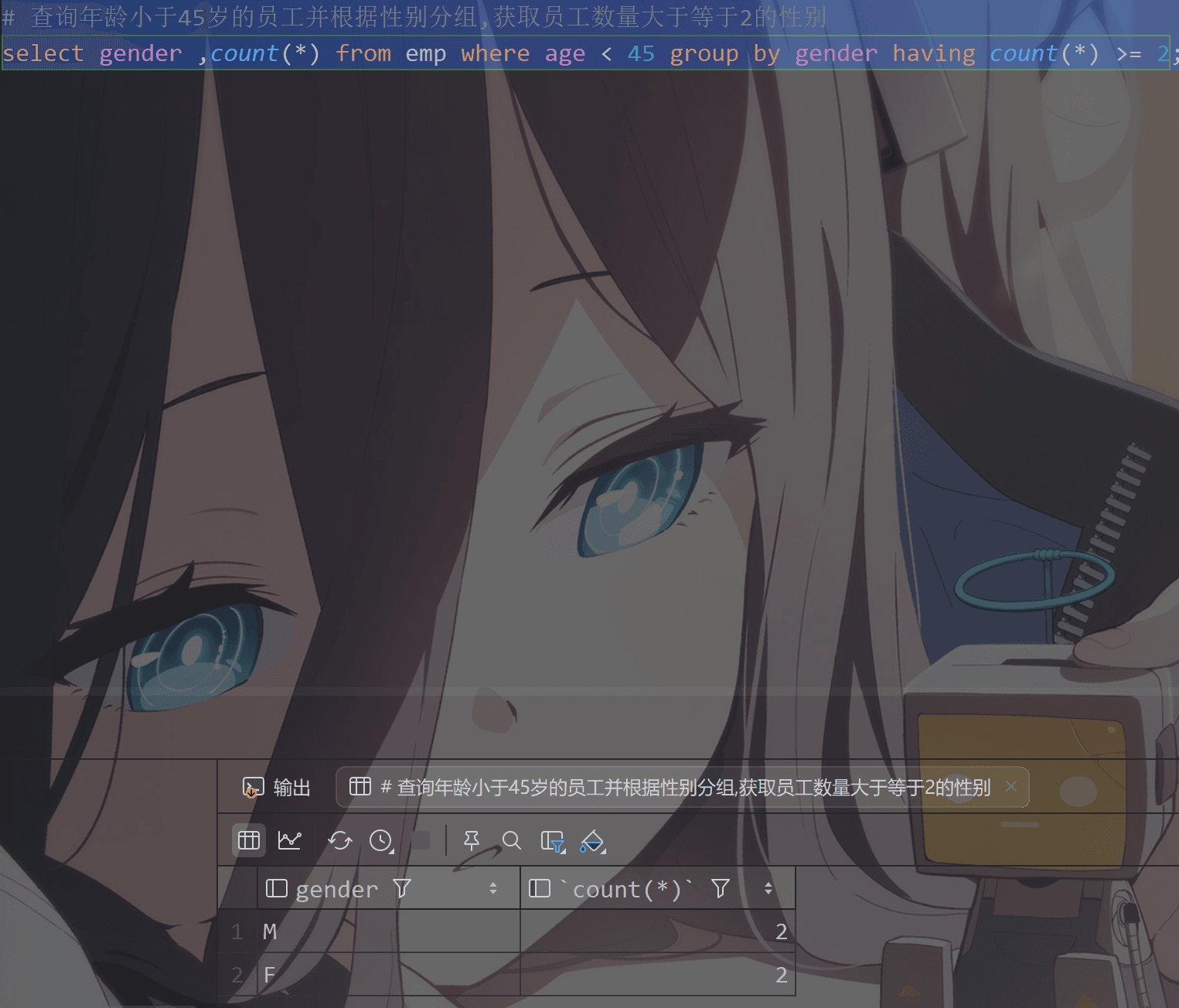
1 | #查询年龄小于45岁的员工并根据性别分组,获取员工数量大于等于2的工作性别 |

⑤ 排序查询

1 | #语法: |
ASC升序
1 | #根据年龄对公司的员工进行升序排序 |

DESC降序
1 | #根据年龄对公司的员工进行降序排序 |
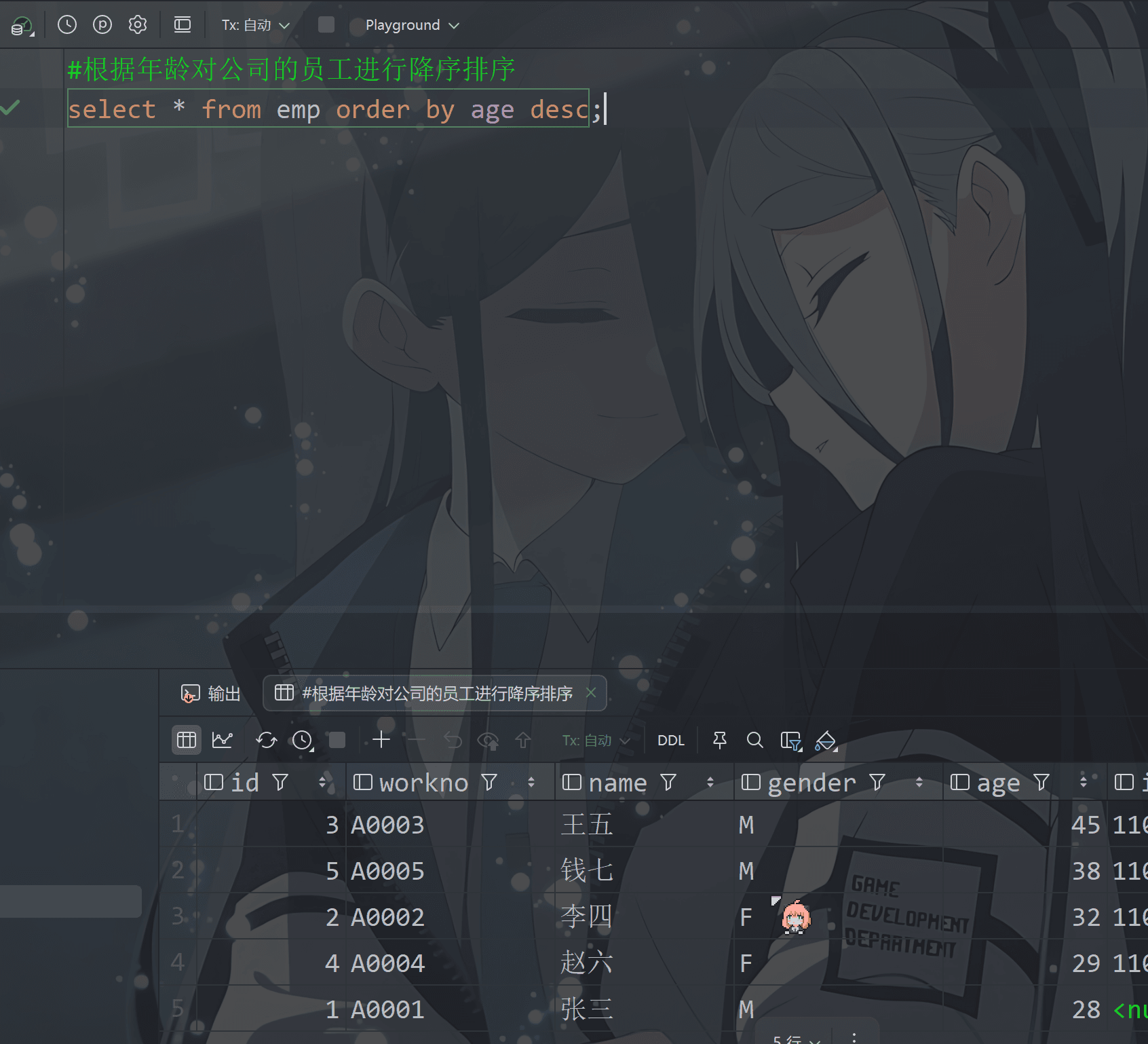
1 | #根据入职时间对员工进行降序排序 |

练习
1 | # 根据年龄对公司的员工进行升序排序,年龄相同,再按照入职时间进行降序排序 |
⑥ 分页查询

1 | #语法: |
这里
1 | #查询第一页数据,每页展示10条数据 |

但是你可以看到我这个数据太少了,所以就展示了5个,所以我改小一点
1 | #查询第二页数据,每页展示2个数据 计算: (页码-1)*页展示记录数 |

评论区